AWS Certified Solution Architect & Developer & SysOps Administrator Associate
Links
IAM
Users & Groups
IAM: Identity and Access Management, A Global service
- Root account created by default, shouldn’t be used or shared
- Users are people within your organization, and can be grouped
- Groups only contain users, not other groups
- Users don’t have to belong to a group, and user can belong to up to 10 groups
- The user gains the permissions applied to the group through the policy
Note
- IAM Users and Roles are IAM Identities, while User Groups are not and cannot be authenticated or authorized
- User groups are used for collecting users with common needs and then applying IAM permissions policies to them
Policy
- Policies are documents that define permissions and are written in JSON
- Identity-based policies can be applied to users, groups, and roles
- All permissions are implicitly denied by default
- In AWS you apply the least privilege principle: don’t give more permissions than a user needs
Types of Policy
- Identity-based policies
- Attached to users, groups, or roles
- Control what actions an identity can perform, on which resources, and under what conditions
- Resource-based policies – attached to a resource; define permissions for a principal accessing the resource
- IAM permissions boundaries – an advanced feature in which you set the maximum permissions that an identity-based policy can grant to an IAM entity
- Access control lists (ACLs) – control which principals in other accounts can access the resource to which the ACL is attached
- AWS Organizations service control policies (SCP) – specify the maximum permissions for an organization or OU
- Session policies – used with
AssumeRoleAPI actions
Determination Rules
- By default, all requests are implicitly denied (though the root user has full access)
- An explicit allow in an identity-based or resource-based policy overrides this default
- If a permissions boundary, Organizations SCP, or session policy is present, it might override the allow with an implicit deny
- An explicit deny in any policy overrides any allows
IAM Policies Structure
Version: policy language version, always include "2012-10-17"Id: an identifier for the policy(optional)Statement: one or more individual statements(required)Sid: an identifier for the statement(optional)Effect: whether the statement allows or denies access (Allow, Deny)Principal: account | user | role to which this policy applied toAction: list of actions(List, Read, Permissions Management, Write, and Tagging)Resource: list of resources to which the actions applied toCondition: conditions for when this policy is in effect (optional)
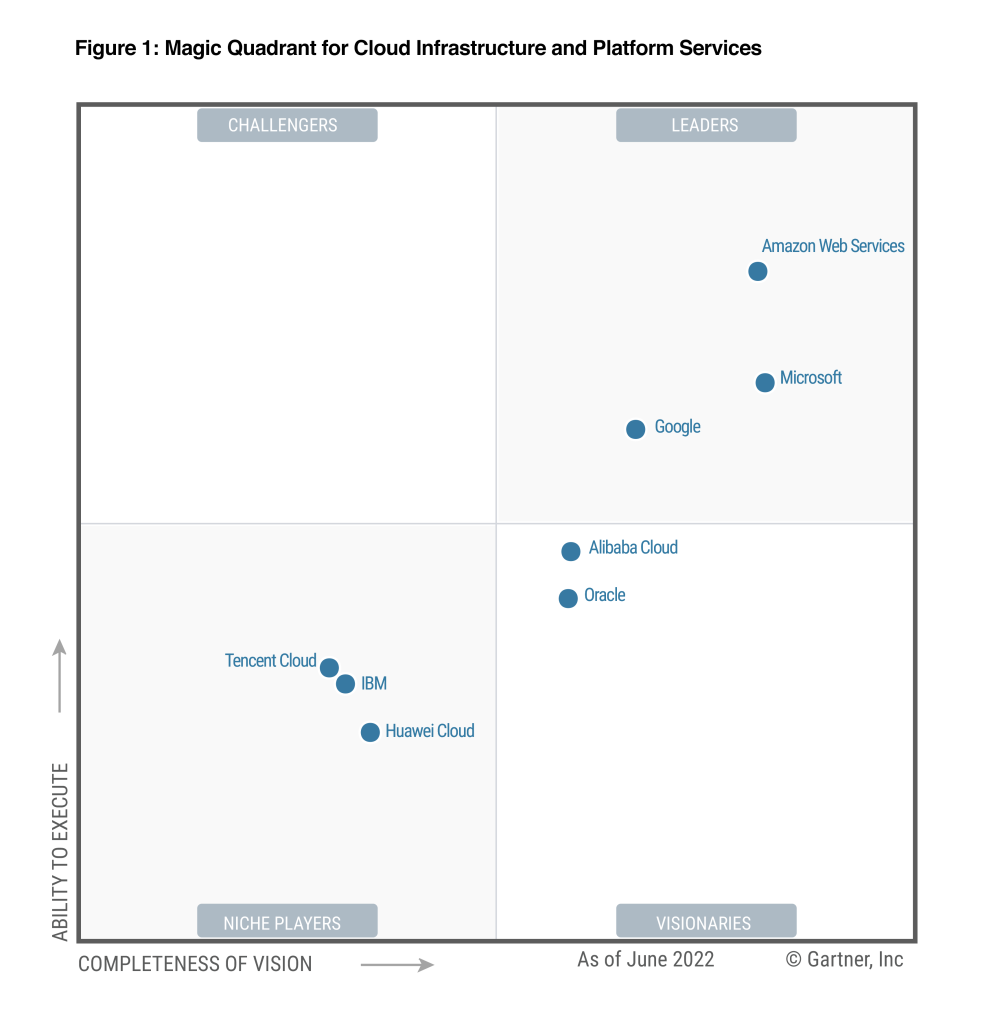
Inline vs Managed Policies
- AWS Managed Policy
- Maintained by AWS
- Good for power users and administrators
- Updated in case of new services / new APIs
- Customer Managed Policy
- Best Practice, re-usable, can be applied to many principals
- Version Controlled + rollback, central change management
- Inline
- Strict one-to-one relationship between policy and principal
- Policy is deleted if you delete the IAM principal
An inline policy is a policy that's embedded in an IAM identity (a user, group, or role)
IAM Security Tools
Credentials Report(account-level)- A report that lists all your account's users and the status of their various credentials
Access Advisor(user-level)- Access advisor shows the service permissions granted to a user and when those services were last accessed.
- You can use this information to revise your policies.
IAM Roles
Some AWS service will need to perform actions on your behalf -> To do so, we will assign permissions to AWS services with IAM Roles
- An IAM role is an IAM identity that has specific permissions
- Roles are assumed by users, applications, and services
- Once assumed, the identity "becomes" the role and gain the roles’ permissions
- Common roles:
- EC2 Instance Roles
- Lambda Function Roles
- Roles for CloudFormation
AWS STS – Security Token Service
- Allows to grant limited and temporary access to AWS resources (up to 1 hour).
- Credentials include:
- AccessKeyId
- Expiration
- SecretAccessKey
- SessionToken
- Trust policies control who can assume the role
- Temporary credentials are used with identity federation, delegation, cross-account access, and IAM roles
- APIs:
sts:AssumeRole: Assume roles within your account or cross accountsts:AssumeRoleWithSAML: return credentials for users logged with SAMLsts:AssumeRoleWithWebIdentity- return creds for users logged with an IdP (Facebook Login, Google Login, OIDC compatible…)
- AWS recommends against using this, and using Cognito Identity Pools instead
sts:GetSessionToken: for MFA, from a user or AWS account root usersts:GetFederationToken: obtain temporary creds for a federated usersts:GetCallerIdentity: return details about the IAM user or role used in the API callsts:DecodeAuthorizationMessage: decode error message when an AWS API is denied
IAM Guidelines & Best Practices
- Don’t use the root account except for AWS account setup
- One physical user = One AWS user
- Assign users to groups and assign permissions to groups
- Create a strong password policy
- Use and enforce the use of Multi Factor Authentication (MFA)
- Create and use Roles for giving permissions to AWS services
- Use Access Keys for Programmatic Access (CLI / SDK)
- Audit permissions of your account with the IAM Credentials Report
- Never share IAM users & Access Keys
- Never ever store IAM key credentials on any machine but a personal computer or on-premise server
- On premise server best practice is to call
AWS Security Token Serviceto obtain temporary security credentials
EC2
EC2: Elastic Compute Cloud
EC2 Instance: AMI (OS) + Instance Size (CPU + RAM) + Storage + security groups + EC2 User Data
Sizing & Configuration Options
- Operating System (OS): Linux, Windows or MacOS
- Compute power & Cores (CPU)
- Random-access Memory (RAM)
- Storage Space:
- Network-attached (EBS & EFS)
- Hardware (EC2 Instance Store)
- Network Card: speed of the card, Public IP address
- Firewall Rules: security group
- Bootstrap Script (configure at first launch): EC2 User Data
EC2 User Data
- It is possible to bootstrap instances using an EC2 User data script
- Bootstrapping means launching commands when a machine starts
- The script only run once at the instance first start
- EC2 user data is used to automate boot tasks such as:
- Installing updates
- Installing software
- Downloading common files from the internet
- Anything you can think of
- The EC2 User Data Script runs with the root user
- Limited to 16 KB
- Batch and PowerShell scripts can be run on Windows
EC2 Meta Data
- Instance metadata is data about your EC2 instance
- Instance metadata is available at
http://169.254.169.254/latest/meta-data
Instance Types
- General Purpose:
- Great for a diversity of workloads such as web servers or code repositories
- Balance between Compute, Memory and Networking
- Compute Optimized:
- Great for compute-intensive tasks that require high performance processors
- Use cases:
- Batch processing workloads
- Media transcoding
- High performance web servers
- High performance computing (HPC)
- Scientific modeling & machine learning
- Dedicated gaming servers
- Memory Optimized:
- Fast performance for workloads that process large data sets in memory
- Use cases:
- High performance, relational/non-relational databases
- Distributed web scale cache stores
- In-memory databases optimized for BI (business intelligence)
- Applications performing real-time processing of big unstructured data
- Storage Optimized:
- Great for storage-intensive tasks that require high, sequential read and write access to large data sets on local storage
- Use cases:
- High frequency online transaction processing (OLTP) systems
- Relational & NoSQL databases
- Cache for in-memory databases (for example, Redis)
- Data warehousing applications
- Distributed file systems
Note
Naming convention:
Exp. m5.2xlarge
- m: instance class
- 5: generation
- 2xlarge: size within the instance class
Tip
Stopping and starting the instance will also move it to different underlying hardware
ECS Instance Lifecycle
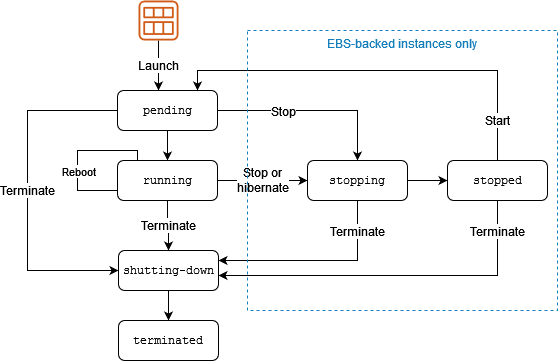
Stopping EC2 instances
- EBS backed instances only
- No charge for stopped instances
- EBS volumes remain attached (chargeable)
- Data in RAM is lost
- Instance is migrated to a different host
- Private IPv4 addresses and IPv6 addresses retained; Public IPv4 addresses released
- Associated Elastic IPs retained
Hibernating EC2 instances
- We know we can stop, terminate instances
- Stop – the data on disk (EBS) is kept intact in the next start
- Terminate – any EBS volumes (root) also set-up to be destroyed is lost
- On start, the following happens:
- First start: the OS boots & the EC2 User Data script is run
- Following starts: the OS boots up
- Then your application starts, caches get warmed up, and that can take time!
- Introducing EC2 Hibernate:
- The in-memory (RAM) state is preserved
- The instance boot is much faster! (the OS is not stopped / restarted)
- Under the hood: the RAM state is written to a file in the root EBS volume
- The root EBS volume must be encrypted
- Applies to on-demand or reserved Linux instances
- Contents of RAM saved to EBS volume
- Must be enabled for hibernation when launched
- Use cases:
- Long-running processing
- Saving the RAM state
- Services that take time to initialize
- When started (after hibernation):
- The EBS root volume is restored to its previous state
- The RAM contents are reloaded
- The processes that were previously running on the instance are resumed
- Previously attached data volumes are reattached and the instance retains its instance ID
- When an EC2 instance is hibernated, the following are charged:
- EBS storage charges for in-memory data saved in EBS volumes
- Elastic IP address charges which are associated with an instance
- Good to know:
- Supported Instance Families – C3, C4, C5, I3, M3, M4, R3, R4, T2, T3, ...
- Instance RAM Size – must be less than 150 GB
- Instance Size – not supported for bare metal instances
- AMI – Amazon Linux 2, Linux AMI, Ubuntu, RHEL, CentOS & Windows...
- Root Volume – must be encrypted EBS, not instance store
- Available for On-Demand, Reserved and Spot Instances
- An instance can NOT be hibernated more than 60 days
Rebooting EC2 instances
- Equivalent to an OS reboot
- DNS name and all IPv4 and IPv6 addresses retained
- Does not affect billing
Retiring EC2 instances
- Instances may be retired if AWS detects irreparable failure of the underlying hardware that hosts the instance
- When an instance reaches its scheduled retirement date, it is stopped or terminated by AWS
Terminating EC2 instances
- Means deleting the EC2 instance
- Cannot recover a terminated instance
- By default root EBS volumes are deleted
Recovering EC2 instances
- CloudWatch can be used to monitor system status checks and recover instance if needed
- Applies if the instance becomes impaired due to underlying hardware / platform issues
- Recovered instance is identical to original instance
Security Groups
- Security groups only contain allow rules
- Security groups rules can reference by IP or by security group
- Security groups are acting as a "firewall" on EC2 instances
- They regulate:
- Type + Protocol
- Control of inbound network (from other to the instance)
- Control of outbound network (from the instance to other)
- Port Range
- Source: Authorised IP ranges – IPv4 and IPv6 / other security group
- Type + Protocol
- Can be attached to multiple instances
- Locked down to a
region/VPCcombination - Does live "outside" the EC2 – if traffic is blocked the EC2 instance won’t see it
- It’s good to maintain one separate security group for SSH access
- If your application is not accessible (time out), then it’s a security group issue
- If your application gives a "connection refused" error, then it’s an application error or it’s not launched
- All inbound traffic is blocked by default
- All outbound traffic is authorized by default
Instances Purchasing Options
On-Demand Instances
- Pay for what you use:
- Amazon Linux, Windows and Ubuntu: billing per second, after the first minute
- MacOS: billing per hour
- Commercial Linux distros such as Red Hat EL and SUSE ES use hourly pricing
- Highest cost but no upfront payment
- No long-term commitment
- Recommended for short-term and un-interrupted workloads, where you can't predict how the application will behave
Reserved Instance
- You reserve a specific instance attributes (Instance Type, Region,Tenancy, OS)
- Payment Options – No Upfront (+discount), Partial Upfront (++discount), All Upfront (+++discount)
- Reserved Instance’s Scope – Regional or Zonal (reserve capacity in an AZ)
- Recommended for steady-state usage applications (think database)
- You can buy and sell in the Reserved Instance Marketplace
- Standard RI - Change AZ, instance size (Linux), networking type - Use
ModifyReservedInstancesAPI - Convertible RI - Change AZ, instance size (Linux), networking type + Change family, OS, tenancy, payment option- Use
ExchangeReservedInstancesAPI
Savings Plans
- 1 or 3-year
- hourly commitment to usage of Fargate, Lambda, and EC2
- Any Region, family, size, tenancy, and OS
- 1 or 3-year
- hourly commitment to usage of EC2 within a selected Region and Instance Family
- Any size, tenancy and OS
Spot Instances
- The most cost-efficient instances in AWS
- 2-minute warning if AWS need to reclaim capacity – available via instance metadata and CloudWatch Events
- Not suitable for critical jobs or databases
- Useful for workloads that are resilient to failure
- Batch jobs
- Data analysis
- Image processing
- Any distributed workloads
- Workloads with a flexible start and end time
Spot Instance Types
- Spot Instance: One or more EC2 instances
- Spot Fleet: launches and maintains the number of Spot / On-Demand instances to meet specified target capacity
- EC2 Fleet: launches and maintains specified number of Spot / On-Demand / Reserved instances in a single API call
- Spot Block: Uninterrupted for 1-6 hours; Pricing is 30% - 45% less than On-Demand
Dedicated Hosts
- A physical server with EC2 instance capacity fully dedicated to your use
- Allows you address compliance requirements and use your existing server-bound software licenses (per-socket, per-core, per—VM software licenses)
- The most expensive option
- Purchasing Options:
- On-demand – pay per second for active Dedicated Host
- Reserved - 1 or 3 years (No Upfront | Partial Upfront | All Upfront)
- Useful for software that have complicated licensing model (BYOL – Bring Your Own License) Or for companies that have strong regulatory or compliance needs
Dedicated Instances
- Instances run on hardware that’s dedicated to you - no other customers will share your hardware
- May share hardware with other instances in same account
- No control over instance placement (can move hardware after Stop / Start)
Capacity Reservations
- Reserve On-Demand instances capacity in a specific AZ for any duration
- You always have access to EC2 capacity when you need it
- no time commitment (create/cancel anytime), no billing discounts
- Combine with Regional Reserved Instances and Savings Plans to benefit from billing discounts
- You’re charged at On-Demand rate whether you run instances or not
- Suitable for short-term, uninterrupted workloads that needs to be in a specific AZ
Spot Fleets
Spot Fleets = set of Spot Instances + (optional) On-Demand Instances
- The Spot Fleet will try to meet the target capacity with price constraints
- Define possible launch pools: instance type (Exp. m5.large), OS, Availability Zone
- Can have multiple launch pools, so that the fleet can choose
- Spot Fleet stops launching instances when reaching capacity or max cost
- Strategies to allocate Spot Instances:
lowestPrice: from the pool with the lowest price (cost optimization, short workload)diversified: distributed across all pools (great for availability, long workloads)capacityOptimized: pool with the optimal capacity for the number of instances
- Spot Fleets allow us to automatically request Spot Instances with the lowest price
AMI
AMI: Amazon Machine Image
- AMI are a customization of an EC2 instance
- You add your own software, configuration, operating system, monitoring...
- Faster boot / configuration time because all your software is pre-packaged
- AMI are built for a specific region (and can be copied across regions)
- You can launch EC2 instances from:
- Public AMIs: AWS provided, free to use, generally you just select the operating system you want
- AWS Marketplace AMIs: an AMI someone else made (and potentially sells) - generally come packaged with additional, licensed software
- Your own AMI: you make and maintain them yourself
- AMI Process(from an EC2 instance)
- Start an EC2 instance and customize it
- Stop the instance (for data integrity)
- Build an AMI – this will also create EBS snapshots
- Launch instances from other AMIs
- An AMI includes the following:
- One or more EBS snapshots OR for instance-store-backed AMIs - a template for the root volume of the instance
- Launch permissions that control which AWS accounts can use the AMI to launch instances
- A block device mapping that specifies the volumes to attach to the instance when it's launched
Tip
It's not possible to move an existing instance to another subnet, Availability Zone, or VPC.
Instead, you can manually migrate the instance by creating a new Amazon Machine Image (AMI) from the source instance.
Then, launch a new instance using the new AMI in the desired subnet, Availability Zone, or VPC.
Finally, you can reassign any Elastic IP addresses from the source instance to the new instance.
EC2 Image Builder
- Used to automate the creation of Virtual Machines or container images
- Automate the creation, maintain, validate and test EC2 AMIs
- Can be run on a schedule (weekly, whenever packages are updated, etc...)
- Free service (only pay for the underlying resources)
EC2 Instance Store
high-performance hardware disk
- Better I/O performance
- EC2 Instance Store lose their storage if they’re stopped (ephemeral)
- Good for buffer / cache / scratch data / temporary content
- Risk of data loss if hardware fails
- Backups and Replication are your responsibility
- Instance Store volumes are physically attached to the host
Placement Groups
Control over the EC2 Instance placement strategy

Cluster
clusters instances into a low-latency group in a single Availability Zone
- Pros: Great network (10 Gbps bandwidth between instances with Enhanced Networking enabled - recommended)
- Cons: If the rack fails, all instances fails at the same time
- Use case:
- Big Data job that needs to complete fast
- Application that needs extremely low latency and high network throughput
Spread
spreads instances across underlying hardware (max 7 instances per group per AZ)
- Pros:
- Can span across AvailabilityZones (AZ)
- Reduced risk is simultaneous failure
- EC2 Instances are on different physical hardware
- Cons:
- Limited to 7 instances per AZ per placement group
- Use case:
- Application that needs to maximize high availability
- Critical Applications where each instance must be isolated from failure from each other
Partition
spreads instances across many different partitions (which rely on different sets of racks) within an AZ. Scales to 100s of EC2 instances per group (Hadoop, Cassandra, Kafka)
- Up to 7 partitions per AZ
- Can span across multiple AZs
- Up to 100s of EC2 instances
- The instances in a partition do not share racks with the instances in the other partitions
- A partition failure can affect many EC2 but won’t affect other partitions
- EC2 instances get access to the partition information as metadata
- Use cases: HDFS, HBase, Cassandra, Kafka
Rules and Limitations
- Placement groups can't cross regions
- An instance can be launched in one placement group at a time; it cannot span multiple placement groups
- You can't merge placement groups
- A cluster placement group can't span multiple Availability Zones
- A partition placement group supports a maximum of 7 partitions per Availability Zone
- A rack spread placement group supports a maximum of 7 running instances per Availability Zone
Network Interfaces (ENI, ENA, EFA)
ENI - Elastic Network Interface
Logical component in a VPC that represents a virtual network card
- The ENI can have the following attributes:
- Primary private IPv4, one or more secondary IPv4
- One Elastic IP (IPv4) per private IPv4
- One Public IPv4(optional)
- One or more security groups
- A MAC address
- You can create ENI independently and attach them on the fly (move them) on EC2 instances for failover
- Additional ENIs can be attached from subnets within the same AZ
- The primary network interface has a private IP and optionally a public IP
- You cannot attach ENIs from subnets in different AZs
- Bound to a specific availability zone (AZ)
- Can use with all instance types
ENA - Elastic Network Adapter
- Enhanced networking performance
- Higher bandwidth and lower inter-instance latency
- Must choose supported instance type
EFA - Elastic Fabric Adapter
- Use with High Performance Computing and MPI and ML use cases
- Tightly coupled applications
- Can use with all instance types
Public, Private and Elastic IP addresses
- Public IP Address:
- Lost when the instance is stopped
- Used in Public Subnets
- No charge
- Associated with a private IP address on the instance
- Cannot be moved between instances
- Private IP Address:
- Retained when the instance is stopped
- Used in Public and Private Subnets
- Elastic IP Address:
- Static Public IP address
- You are charged if not used
- Associated with a private IP address on the instance
- Can be moved between instances and Elastic Network Adapters
AWS Nitro System
Nitro is the underlying platform for the next generation of EC2 instances
- Support for many virtualized and bare metal instance types
- Breaks functions into specialized hardware with a Nitro Hypervisor
- Specialized hardware includes:
- Nitro cards for VPC
- Nitro cards for EBS
- Nitro for Instance Storage
- Nitro card controller
- Nitro security chip
- Nitro hypervisor
- Nitro Enclaves
- Improves performance, security and innovation:
- Performance close to bare metal for virtualized instances
- Elastic Network Adapter and Elastic Fabric Adapter
- More bare metal instance types
- Higher network performance (e.g. 100 Gbps)
- High Performance Computing (HPC) optimizations
- Dense storage instances (e.g. 60 TB)
AWS Nitro Enclaves

- Isolated compute environments
- Runs on isolated and hardened virtual machines
- No persistent storage, interactive access, or external networking
- Uses cryptographic attestation to ensure only authorized code is running
- Integrates with AWS Key Management Service (KMS)
- Protect and securely process highly sensitive data:
- Personally identifiable information (PII)
- Healthcare data
- Financial data
- Intellectual Property data
EBS
An EBS (Elastic Block Store) Volume is a network drive you can attach to your instances while they run
- It’s a network drive (i.e. not a physical drive)
- It uses the network to communicate the instance, which means there might be a bit of latency
- It can be detached from an EC2 instance and attached to another one quickly
- It’s locked to an Availability Zone (AZ)
- To move a volume across, you first need to snapshot it
- Have a provisioned capacity (size in GBs, and IOPS)
- You get billed for all the provisioned capacity
- You can increase the capacity of the drive over time
- Delete on Termination attribute:
- Controls the EBS behaviour when an EC2 instance terminates
- By default, the root EBS volume is deleted (attribute enabled)
- By default, any other attached EBS volume is not deleted (attribute disabled)
- This can be controlled by the AWS console / AWS CLI
Resizing EBS Volumes
After you increase the size of an EBS volume, use the Windows Disk Management utility or PowerShell to extend the disk size to the new size of the volume.
You can begin resizing the file system as soon as the volume enters the optimizing state.
EBS Snapshots
- Make a backup (snapshot) of your EBS volume at a point in time
- Not necessary to detach volume to do snapshot, but recommended
- Can copy snapshots across AZ or Region
- EBS Snapshot Archive:
- Move a snapshot to an "archive tier" which is cheaper
- Takes within 24 to 72 hours for restoring the archive
- EBS Snapshots Features:
- EBS Snapshot Archive
- Move a Snapshot to an 'archive tier' that is much cheaper
- Takes within 24 to 72 hours for restoring the archive
- Recycle Bin for EBS Snapshots
- Setup rules to retain deleted snapshots so you can recover them after an accidental deletion
- Specify retention(from 1 day to 1 year)
- Fast Snapshot Restore(FSR)
- Force full initialization of snapshot to have no latency on the first use($$$)
- Fast Snapshot restore (FSR) needs to be enabled per Availability Zone
- This can be enabled on both existing as well as new Snapshots
- EBS Snapshot Archive
Tip
Amazon EBS direct APIs can be used to create EBS snapshots, write data directly to snapshots, read data from snapshots, and identify the difference between two snapshots.
Note
There can be an initial performance hit when an Amazon EBS volume is created from snapshots. This can be avoided by either of the following:
- Force the immediate initialization of the entire volume.
- Enable fast snapshot to restore on a snapshot to ensure that the EBS volumes are fully initialized.
EBS Volume Types
- EBS Volumes come in 6 types
- gp2 / gp3 (SSD): General purpose SSD volume that balances price and performance for a wide variety of workloads
- io1 / io2 (SSD): Highest-performance SSD volume for mission-critical low-latency or high-throughput workloads
- st1 (HDD): Low cost HDD volume designed for frequently accessed, throughput-intensive workloads
- sc1 (HDD): Lowest cost HDD volume designed for less frequently accessed workloads
- EBS Volumes are characterized in Size | Throughput | IOPS (I/O Ops Per Sec)
- Only gp2/gp3 and io1/io2 can be used as boot volumes

EBS vs Instance Store
- EBS volumes are attached over the network, while Instance Store volumes are physically attached to the host and offer high - performance
- EBS volumes offer persistent storage, while Instance Store volumes are ephemeral(non-persistent)
EBS Multi-Attach – io1/io2 family
- Attach the same EBS volume to multiple EC2 instances in the same AZ
- Available for Nitro system-based EC2 instances
- Up to 16 instances can be attached to a single volume
- Each instance has full read & write permissions to the volume
- Use case:
- Achieve higher application availability in clustered Linux applications
- Applications must manage concurrent write operations
- Must use a file system that’s cluster-aware (not XFS, EX4, etc...)
Copying and Sharing AMIs and Snapshots
- Encrypted Snapshot -> Encrypted AMI
- Can be shared with other accounts(custom key only)
- Cannot be shared publicly
- Encrypted AMI -> Encrypted AMI
- Can change encryption key
- Can change region
- Encrypted AMI -> EC2 Instance
- Can change encryption key
- Can change AZ
- Unencrypted AMI -> EC2 Instance
- Can change encryption state
- Can change AZ
- Encrypted Snapshot -> Encrypted Volume
- Can be encrypted
- Can change AZ
Amazon Data Lifecycle Manager(DLM)
- DLM automates the creation, retention, and deletion of EBS snapshots and EBS-backed AMIs
- DLM helps with the following:
- Protects valuable data by enforcing a regular backup schedule
- Create standardized AMIs that can be refreshed at regular intervals
- Retain backups as required by auditors or internal compliance
- Reduce storage costs by deleting outdated backups
- Create disaster recovery backup policies that back up data to isolated accounts
EBS Encryption
- When you create an encrypted EBS volume, you get the following:
- Data at rest is encrypted inside the volume
- All the data in flight moving between the instance and the volume is encrypted
- All snapshots are encrypted
- All volumes created from the snapshot
- Encryption and decryption are handled transparently (you have nothing to do)
- Encryption has a minimal impact on latency
- EBS Encryption leverages keys from KMS (AES-256)
- Copying an unencrypted snapshot allows encryption
- Snapshots of encrypted volumes are encrypted
Using RAID with EBS
RAID stands for Redundant Array of Independent disks
- Not provided by AWS, you must configure through your operating system
- RAID 0 and RAID 1 are potential options on EBS
- RAID 0 is used for striping data across disks (performance)
- RAID 1 is used for mirroring data across disks (redundancy / fault tolerance)
- RAID 5 and RAID 6 are not recommended by AWS
EFS
EFS: Elastic File System
- Managed NFS (network file system) that can be simultaneously mounted on thousands of EC2
- Appliances are known as Network Attached Storage (NAS) devices for both SMB / CIFS and NFS
- Can connect instances from other VPCs and on-premises computers
- EFS works with Linux EC2 instances in multi-AZ - POSIX file system that has a standard file API
- Encryption at rest using KMS can be enabled when creating the file system
- Encryption during transit can be enabled when mounting the file system using the
Amazon EFS mount helper. The mount helper uses TLS version 1.2 to communicate with the file system. - Highly available, scalable, expensive (3x gp2), pay per use, no capacity planning
- EFS Infrequent Access (EFS-IA): Storage class that is cost-optimized for files not accessed every day
- Use cases:
- content management
- web serving
- data sharing
- Wordpress
Tip
Once you create an EFS file system, you cannot change its encryption setting.
This means that you cannot modify an unencrypted file system to make it encrypted. Instead, you need to create a new, encrypted file system.
Tip
Mount command: mount –t nfs servername:folderpath /mountpoint
EFS Performance
- EFS Scale
- 1000s of concurrent NFS clients, 10 GB+/s throughput
- Grow to Petabyte-scale network file system, automatically
- Performance mode (set at EFS creation time)
- General purpose(default): latency-sensitive use cases(webserver, CMS, etc...)
- Max I/O – higher latency, throughput, highly parallel (big data, media processing, etc...)
- Throughput mode
- Bursting (1TB = 50MiB/s + burst of up to 100MiB/s)
- Provisioned:set your throughput regardless of storage size,ex: 1GiB/s for 1TB storage
EFS Storage Classes
- Storage Tiers (lifecycle management feature – move file after N days)
- Standard: for frequently accessed files
- Infrequent access (EFS-IA): cost to retrieve files, lower price to store. Enable EFS-IA with a Lifecycle Policy
- Availability and durability
- Standard: Multi-AZ, great for prod
- One Zone: One-AZ, great for dev, backup enabled by default, compatible with IA (EFS One Zone-IA)
Tip
Amazon EFS Standard-IA storage class can be used to store data that is infrequently accessed but requires high availability and durability.
With Amazon EFS Standard-IA storage class, data is stored redundantly across multiple AZ.
Mount Targets
- A mount target provides an IP address for an NFSv4 endpoint at which you can mount an Amazon EFS file system.
- You mount your file system using its Domain Name Service (DNS) name, which resolves to the IP address of the EFS mount target in the same Availability Zone as your EC2 instance.
- You can create one mount target in each Availability Zone in an AWS Region
- If there are multiple subnets in an Availability Zone in your VPC, you create a mount target in one of the subnets. Then all EC2 instances in that Availability Zone share that mount target.
Amazon FSx
- Launch fully managed 3rd party high-performance file systems on AWS
- Fully managed service
- Amazon FSx for Windows File Server: A fully managed, highly reliable, and scalable native Windows shared file system
- Built on Windows File Server
- Full supports SMB protocol & Windows NTFS
- Integrated with Microsoft Active Directory
- Can be accessed from AWS or your on-premise infrastructure
- Supports Windows-native file system features:
- Access Control Lists (ACLs), shadow copies, and user quotas
- NTFS file systems that can be accessed from up to thousands of compute instances using the SMB protocol
- High availability: replicates data within an Availability Zone (AZ)
- Multi-AZ: file systems include an active and standby file server in separate AZs
- Amazon FSx for Lustre: A fully managed, high-performance, scalable file storage for High Performance Computing (HPC)
- High-performance file system optimized for fast processing of workloads such as:
- Machine learning
- High performance computing (HPC)
- Video processing
- Financial modeling
- Electronic design automation (EDA)
- Works natively with S3, letting you transparently access your S3 objects as files
- Your S3 objects are presented as files in your file system, and you can write your results back to S3
- Provides a POSIX-compliant file system interface
- High-performance file system optimized for fast processing of workloads such as:
Tip
The name Lustre is derived from "Linux" and "cluster"
Note
With Multi-AZ deployment, active and standby servers are placed in separate AZ. Data written to an active server is synchronously replicated to standby servers.
With Synchronous replication, data is written to active and standby servers simultaneously, while with asynchronous replication, there might be a lag between data written to active servers and standby servers.
Synchronous Replication is advantageous during failover where standby servers are in sync with active servers.
ELB & ASG
ELB: Elastic Load Balancing
ASG: Auto Scaling Group
High Availability & Scalability
- Vertical Scaling: Increase instance size (scale up / down)
- Horizontal Scaling: Increase number of instances (scale out / in)
- High Availability:
- Usually goes hand in hand with horizontal scaling
- Run instances for the same application across multi AZ
- Auto Scaling Group multi AZ
- Load Balancer multi AZ
- The goal of high availability is to survive a data center loss
- The high availability can be passive(exp. RDS Multi AZ)
- The high availability can be active(for horizontal scaling)
Scalability vs Elasticity vs Agility
Scalability: ability to accommodate a larger load by making the hardware stronger (scale up), or by adding nodes (scale out)Elasticity: once a system is scalable, elasticity means that there will be some "auto-scaling" so that the system can scale based on the load.This is "cloud-friendly": pay-per-use, match demand, optimize costsAgility: new IT resources are only a click away, which means that you reduce the time to make those resources available to your developers from weeks to just minutes.
Elastic Load Balancer
- An ELB (Elastic Load Balancer) is a managed load balancer
- AWS guarantees that it will be working
- AWS takes care of upgrades, maintenance, high availability
- AWS provides only a few configuration knobs
- It costs less to setup your own load balancer but it will be a lot more effort on your end (maintenance, integrations)
Application Load Balancer
- Operates at the request level
- Layer 7(HTTP / HTTPS / gRPC) only
- Load balancing to multiple applications across machines (target groups)
- Load balancing to multiple applications on the same machine (ex: containers)
- Support for HTTP/2 and WebSocket
- Support redirects (from HTTP to HTTPS for example)
- Routing tables to different target groups:
- Routing based on path in URL (example.com/users & example.com/posts)
- Routing based on hostname in URL (one.example.com & other.example.com)
- Routing based on Query String, Headers (example.com/users ?id=123&order=false)
- Routing based on source IP
- a great fit for micro services & container-based application (example: Docker & Amazon ECS)
- Has a port mapping feature to redirect to a dynamic port in ECS
- Target Groups:
- EC2 instances (can be managed by an Auto Scaling Group) – HTTP
- ECS tasks (managed by ECS itself) – HTTP
- Lambda functions – HTTP request is translated into a JSON event
- IP Addresses – must be private IPs
- Fixed hostname (XXX.<region>.elb.amazonaws.com)
- The application servers don’t see the IP of the client directly
- The true IP of the client is inserted in the header
X-Forwarded-For - We can also get Port (
X-Forwarded-Port) and Proto (X-Forwarded-Proto)
- The true IP of the client is inserted in the header
- Use Cases:
- Web applications with L7 routing (HTTP/HTTPS)
- Microservices architectures (e.g. Docker containers)
- Lambda targets
Network Load Balancer
- Operates at the connection level
- Ultra-high performance, allows for TCP(Layer 4):
- Forward TCP & UDP traffic to your instances
- Handle millions of request per seconds
- Less latency(~100 ms)
- Requests are routed based on IP protocol data
- NLB has one static IP per AZ, and supports assigning Elastic IP (helpful for whitelisting specific IP)
- NLB nodes can have elastic IPs in each subnet
- NLB are used for extreme performance, TCP or UDP traffic
- NLBs listen on TCP, TLS, UDP or TCP_UDP
- A separate listener on a unique port is required for routing
- Not included in the AWS free tier
- Health Checks support the TCP, HTTP and HTTPS Protocols
- Target Groups
- EC2 instances
- IP Addresses – must be private IPs
- Application Load Balancer
- On-Premises
- Use Cases:
- TCP and UDP based applications
- Ultra-low latency
- Static IP addresses
- VPC endpoint services
Gateway Load Balancer
- Used in front of virtual appliances
- Example: Firewalls, Intrusion Detection and Prevention Systems, Deep Packet Inspection Systems, payload manipulation, ...
- Operates at Layer 3 (Network Layer) – listens for all packets on all ports
- Forwards traffic to the TG specified in the listener rules
- Exchanges traffic with appliances using the GENEVE protocol on port 6081
- Deploy, scale, and manage a fleet of 3rd party network virtual appliances in AWS
- Combines the following functions:
- Transparent Network Gateway – single entry/exit for all traffic
- Load Balancer – distributes traffic to your virtual appliances
- Target Groups
- EC2 instances
- IP Addresses – must be private IPs
- Use Case:
- Load balance virtual appliances such as:
- Intrusion detection systems (IDS)
- Intrusion prevention systems (IPS)
- Next generation firewalls (NGFW)
- Web application firewalls (WAF)
- Distributed denial of service protection systems (DDoS)
- Integrate with Auto Scaling groups for elasticity
- Apply network monitoring and logging for analytics
- Load balance virtual appliances such as:
Load Balancer - SSL Certificates
Note
- An SSL Certificate allows traffic between your clients and your load balancer to be encrypted in transit (in-flight encryption)
- SSL refers to Secure Sockets Layer, used to encrypt connections
- TLS refers to Transport Layer Security, which is a newer version
- Nowadays, TLS certificates are mainly used, but people still refer as SSL
- Public SSL certificates are issued by Certificate Authorities (CA)
- Comodo, Symantec, GoDaddy, GlobalSign, Digicert, Letsencrypt, etc...
- SSL certificates have an expiration date (you set) and must be renewed
- The load balancer uses an X.509 certificate (SSL/TLS server certificate)
- You can manage certificates using
ACM(AWS Certificate Manager) - You can create upload your own certificates alternatively
- HTTPS listener:
- You must specify a default certificate
- You can add an optional list of certs to support multiple domains
- Clients can use SNI (Server Name Indication) to specify the hostname they reach
- Ability to specify a security policy to support older versions of SSL /TLS (legacy clients)
SSL – Server Name Indication (SNI)
SNI solves the problem of loading multiple SSL certificates onto one web server (to serve multiple websites)
- It’s a "newer" protocol, and requires the client to indicate the hostname of the target server in the initial SSL handshake
- The server will then find the correct certificate, or return the default one
- Note:
- Only works for ALB & NLB (newer generation), CloudFront
- Does not work for CLB (older gen)
Cross-Zone Load Balancing
- Application Load Balancer
- Always on (can’t be disabled)
- No charges for inter-AZ data
- Network Load Balancer
- Disabled by default
- You pay charges ($) for inter-AZ data if enabled
Connection Draining
Time to complete "in-flight requests" while the instance is de-registering or unhealthy
- Stops sending new requests to the EC2 instance which is de-registering
- Between 1 to 3600 seconds (default: 300 seconds)
- Can be disabled (set value to 0)
- Set to a low value if your requests are short
ELB Access Logs
ELB access logs are an optional feature that can be used to troubleshoot traffic patterns and issues with traffic as it hits the ELB.
- ELB access logs capture details of requests sent to your load balancer such as:
- The time of the request
- The client IP
- Latency
- Server responses
- Access logs are stored in an S3 bucket. Log files are published every five minutes, and multiple logs can be published for the same five-minute period.
- ELB access logs also include HTTP response codes from the target.
- Disabled by default
Note
- The S3 bucket must be in the same region as the ELB.
- The bucket policy must be configured to allow access logs to write to the bucket.
- You can use tools such as Amazon Athena, Loggly, Splunk, or Sumo Logic to analyze the contents of ELB access logs.
Auto Scaling Group
- In real-life, the load on your websites and application can change
- In the cloud, you can create and get rid of servers very quickly
- The goal of an Auto Scaling Group (ASG) is to:
- Scale out (add EC2 instances) to match an increased load
- Scale in (remove EC2 instances) to match a decreased load
- Ensure we have a minimum and a maximum number of machines running
- Automatically register new instances to a load balancer
- Replace unhealthy instances
- Cost Savings: only run at an optimal capacity (principle of the cloud)
Note
Automatically scale AWS services including:
- Amazon EC2 – Launch or terminate EC2 instances
- Amazon EC2 Spot Fleets
- Amazon ECS – Adjust ECS service desired count up/down
- Amazon DynamoDB – increase provisioned RCUs/WCUs
- Amazon Aurora – Adjust the number of Read Replicas
Tip
ASG is region bound, you can’t span them across regions
Configuration of an Auto Scaling Group
- A Launch Template specifies the EC2 instance configuration:
- AMI + InstanceType
- EC2 User Data
- EBS Volumes
- Security Groups
- SSH Key Pair
- IAM Roles for your EC2 Instances
- Network + Subnets Information
- Load Balancer Information
- Configure purchase options – On-demand vs Spot
- Configure VPC and Subnets
- Attach Load Balancer
- Configure health checks for EC2 & ELB
- Group size and scaling policies
Monitoring
- It is possible to scale an ASG based on CloudWatch alarms
- An alarm monitors a metric (such as Average CPU, or a custom metric)
- Metrics such as Average CPU are computed for the overall ASG instances
Note
- Group metrics (ASG)
- Data points about the Auto Scaling group
- 1-minute granularity
- No charge
- Must be enabled
- Basic monitoring (Instances)
- 5-minute granularity
- No Charge
- Detailed monitoring (Instances)
- 1-minute granularity
- Charges apply
Scaling Strategies
- Manual Scaling: Update the size of an ASG manually
- Dynamic Scaling: Respond to changing demand
- Target Tracking Scaling
- Most simple and easy to set-up
- Example: the average ASG CPU to stay at around 40%
- Simple / Step Scaling
- When a CloudWatch alarm is triggered (example CPU > 70%), then add 2 units
- When a CloudWatch alarm is triggered (example CPU < 30%), then remove 1 unit
- Scheduled Scaling
- Anticipate a scaling based on known usage patterns
- Example: increase the min capacity to 10 at 5 pm on Fridays
- Target Tracking Scaling
- Predictive Scaling: Uses Machine Learning to predict future traffic ahead of time
Tip
Target tracking is only for unpredictable workloads
Additional Scaling Settings
- Cooldowns – Used with simple scaling policy to prevent Auto Scaling from launching or terminating before effects of previous activities are visible. Default value is 300 seconds (5 minutes)
- Termination Policy – Controls which instances to terminate first when a scale-in event occurs
- Termination Protection – Prevents Auto Scaling from terminating protected instances
- Standby State – Used to put an instance in the InService state into the Standby state, update or troubleshoot the instance
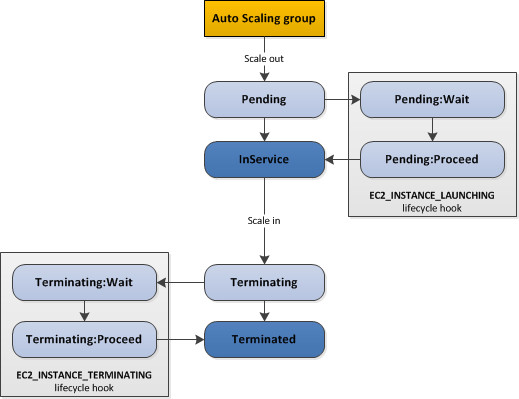
- Lifecycle Hooks – Used to perform custom actions by pausing instances as the ASG launches or terminates them
Global Applications
Route 53
DNS Terminologies
- Domain Registrar: Amazon Route 53, GoDaddy, ...
- DNS Records: A, AAAA, CNAME, NS, ...
- Zone File: contains DNS records
- Name Server: resolves DNS queries (Authoritative or Non-Authoritative)
- Top Level Domain (TLD): .com, .us, .in, .gov, .org, ...
- Second Level Domain (SLD): amazon.com, google.com, ...

Amazon Route 53
- A highly available, scalable, fully managed and Authoritative DNS
- Authoritative = the customer (you) can update the DNS records
- Route 53 is also a Domain Registrar
- Ability to check the health of your resources
- The only AWS service which provides 100% availability SLA
- 53 is a reference to the traditional DNS port
- Features:
- Domain Registration
- Hosted Zone
- Health Checks
- Traffic Flow
Route 53 – Records
- How you want to route traffic for a domain
- Each record contains:
- Domain/subdomain Name
- Record Type
- Value
- Routing Policy – how Route 53 responds to queries
- TTL – amount of time the record cached at DNS Resolvers
- Route 53 supports the following DNS record types:
- (must know)A /AAAA / CNAME / NS
A– maps a hostname to IPv4AAAA– maps a hostname to IPv6CNAME– maps a hostname to another hostname- The target is a domain name which must have an A or AAAA record
- Can’t create a CNAME record for the top node of a DNS namespace(Zone Apex) -> use
Aliasinstead - Example: you can’t create for example.com, but you can create for <www.example.com>
NS– Name Servers for the Hosted Zone- Control how traffic is routed for a domain
- (advanced)CAA/DS/MX/NAPTR/PTR/SOA/TXT/SPF/SRV
- (must know)A /AAAA / CNAME / NS

Route 53 – Hosted Zones
- A container for records that define how to route traffic to a domain and its subdomains
- Public Hosted Zones
- contains records that specify how to route traffic on the Internet (public domain names)
- Exp. application1.
mypublicdomain.com
- Private Hosted Zones
- contain records that specify how you route traffic within one or more VPCs (private domain names)
- Exp. application1.
company.internal
- You pay $0.50 per month per hosted zone
Note
When you create a hosted zone, Route 53 automatically creates a name server (NS) record and a start of authority (SOA) record for the zone.
Migration to/from Route 53
- You can migrate from another DNS provider and can import records
- You can migrate a hosted zone to another AWS account
- You can migrate from Route 53 to another registrar
- You can also associate a Route 53 hosted zone with a VPC in another account
- Authorize association with VPC in the second account
- Create an association in the second account
Records TTL(Time To Live)
- High TTL – e.g., 24 hr
- Less traffic on Route 53
- Possibly outdated records
- Low TTL – e.g., 60 sec.
- More traffic on Route 53 ($$)
- Records are outdated for less time
- Easy to change records
Note
Except for Alias records,TTL is mandatory for each DNS record
CNAME vs Alias
- Points a hostname to any other hostname (acme.example.com to zenith.example.com or to acme.example.org)
- Can redirect DNS queries to any DNS record
- ONLY FOR NON ROOT DOMAIN (aka. something.mydomain.com)
- Points a hostname to an AWS Resource (app.mydomain.com => blabla.amazonaws.com)
- Works for ROOT DOMAIN and NON ROOT DOMAIN (aka mydomain.com)
- An extension to DNS functionality
- Automatically recognizes changes in the resource's IP addresses
- Alias Record is always of type A/AAAA for AWS resources
- You can't set the TTL
- Free of charge
- Native health check
- Records Targets:
- Elastic Load Balancers
- CloudFront Distributions
- API Gateway
- Elastic Beanstalk environments
- S3 Websites
- VPC Interface Endpoints
- Global Accelerator accelerator
- Route 53 record in the same hosted zone
- You can't set an ALIAS record for an EC2 DNS name
Route 53 – Routing Policies
Note
- Define how Route 53 responds to DNS queries
- Routing:
- It’s not the same as Load balancer routing which routes the traffic
- DNS does not route any traffic, it only responds to the DNS queries
Route 53 Supports the following Routing Policies:
- Simple DNS response providing the IP address associated with a name
- Can specify multiple values in the same record
- If multiple values are returned, a random one is chosen by the client
- When Alias enabled, specify only one AWS resource
- Can’t be associated with Health Checks
- Uses the relative weights(actually use an integer between 0 and 255) assigned to resources to determine which to route to
- Assign each record a relative weight(weights don't need to sum up to 100)
- DNS records must have the same name and type
- Can be associated with Health Checks
- Use cases: load balancing between regions, testing new application versions...
- Assign a weight of 0 to a record to stop sending traffic to a resource
- If all records have weight of 0, then all records will be returned equally
- If primary is down (based on health checks), routes to secondary destination
- Health check is required on Primary
- Redirect to the resource that has the least latency close to us
- Super helpful when latency for users is a priority
- Latency is based on traffic between users and AWS Regions
- Japan users may be directed to the US (if that’s the lowest latency)
- Can be associated with Health Checks (has a failover capability)
- Different from Latency-based!
- This routing is based on user geographic location
- Specify location by Continent, Country or by US State (if there’s overlapping, most precise location selected)
- Should create a "Default" record (in case there’s no match on location)
- Use cases: website localization, restrict content distribution, load balancing, ...
- Can be associated with Health Checks
- You can use geolocation routing to create records in a private hosted zone
- Use when routing traffic to multiple resources
- Returns several IP addresses and functions as a basic load balancer
- Can be associated with Health Checks (return only values for healthy resources)
- Up to 8 healthy records are returned for each Multi-Value query
- Multi-Value is not a substitute for having an ELB
- Using Route 53 Traffic Flow feature
- Route traffic to your resources based on the geographic location of users and resources
- Ability to shift more traffic to resources based on the defined bias
- You must use Route 53 Traffic Flow to use this feature
Route 53 – Calculated Health Checks
- Combine the results of multiple Health Checks into a single Health Check
- You can use OR, AND, or NOT
- Can monitor up to 256 Child Health Checks
- Specify how many of the health checks need to pass to make the parent pass
- Usage: perform maintenance to your website without causing all health checks to fail
AWS CloudFront
Content Delivery Network (CDN):
- Improves read performance, content is cached at the edge
- Improves users experience
- 450+ Point of Presence globally (edge locations)
- DDoS protection, integration with Shield, AWS Web Application Firewall
CloudFront Origin Access Control (OAC)
- Like a Signed OAI but supports additional use cases
- AWS recommend the OAC for the following use cases:
- Amazon S3 server-side encryption with AWS KMS (SSE-KMS)
- All Amazon S3 buckets in all AWS Regions
- Dynamic requests (PUT and DELETE) to Amazon S3
- Requires an S3 bucket policy that allows the CloudFront service principal
Origins
- For distributing files and caching them at the edge
- Enhanced security with CloudFront Origin Access Control (OAC)
- OAC is replacing Origin Access Identity(OAI)
- CloudFront can be used as an ingress (to upload files to S3)
- Application Load Balancer
- EC2 instance
- S3 website (must first enable the bucket as a static S3 website)
- Any HTTP backend you want
Tip
The uses cases for origin custom headers are:
- Identifying requests from CloudFront
- Determining which requests come from a particular distribution
- Enabling cross-origin resource sharing (CORS)
- Controlling access to content
If the header names and values that you specify are not already present in the viewer request, CloudFront adds them to the origin request.
If a header is present, CloudFront overwrites the header value before forwarding the request to the origin.
Geo Restriction
- You can restrict who can access your distribution
- Whitelist: Allow your users to access your content only if they're in one of the countries on a list of approved countries.
- Blacklist: Prevent your users from accessing your content if they're in one of the countries on a blacklist of banned countries.
- The "country" is determined using a 3rd party Geo-IP database
- Use case: Copyright Laws to control access to content
CloudFront vs S3 Cross Region Replication
- Global Edge network
- Files are cached for a TTL (maybe a day)
- Great for static content that must be available everywhere
- Must be setup for each region you want replication to happen
- Files are updated in near real-time
- Read only
- Great for dynamic content that needs to be available at low-latency in few regions
Price Classes
- You can reduce the number of edge locations for cost reduction
- Three price classes:
- Price Class All: all regions – best performance
- Price Class 200: most regions, but excludes the most expensive regions
- Price Class 100: only the least expensive regions
CloudFront Caching
- Cache based on
- Headers
- Session Cookies
- Query String Parameters
- The cache lives at each CloudFront Edge Location
- You want to maximize the cache hit rate to minimize requests on the origin
- Control the TTL (0 seconds to 1 year), can be set by the origin using the Cache-Control header, Expires header...
- You can invalidate part of the cache using the CreateInvalidation API
Tip
- You can define a maximum TTL and a default TTL
- TTL is defined at the behavior level -> This can be used to define different TTLs for different file types
- After expiration, CloudFront checks the origin for any new requests (check if the file is the latest version)
- Headers can be used to control the cache:
Cache-Control max-age=(seconds)- specify how long before CloudFront gets the object again from the origin serverExpires– specify an expiration date and time
- When the TTL on a file expires, CloudFront forwards the next incoming request to the origin server. If CloudFront has the latest version, the origin returns the status code
304 Not Modified.
CloudFront Signed URL vs S3 Pre-Signed URL
- Allow access to a path, no matter the origin
- Account wide key-pair, only the root can manage it
- Can specify beginning and expiration date and time, IP addresses/ranges of users
- Can leverage caching features
- Issue a request as the person who pre-signed the URL
- Uses the IAM key of the signing IAM principal
- Limited lifetime
Note
Signed URLs should be used for individual files and clients that don’t support cookies
CloudFront Signed Cookies
- Similar to Signed URLs
- Use signed cookies when you don’t want to change URLs
- Can also be used when you want to provide access to multiple restricted files (Signed URLs are for individual files)
CloudFront Access Logs
- Contain detailed information about every user request that CloudFront receives at Edge Locations
- Known as standard logs and stored in S3
- Can log separately for different distributions
- Can also enable real-time logs which are recorded in real time (within seconds)
- Real-time logs can be used to monitor, analyze, and take action based on content delivery performance
- Edge function logs record requests processed by Lambda@Edge and CloudFront Functions
Lambda@Edge
- Lambda functions written in NodeJS or Python
- Scales to 1000s of requests/second
- Used to change CloudFront requests and responses:
- Viewer Request – after CloudFront receives a request from a viewer
- Origin Request – before CloudFront forwards the request to the origin
- Origin Response – after CloudFront receives the response from the origin
- Viewer Response – before CloudFront forwards the response to the viewer
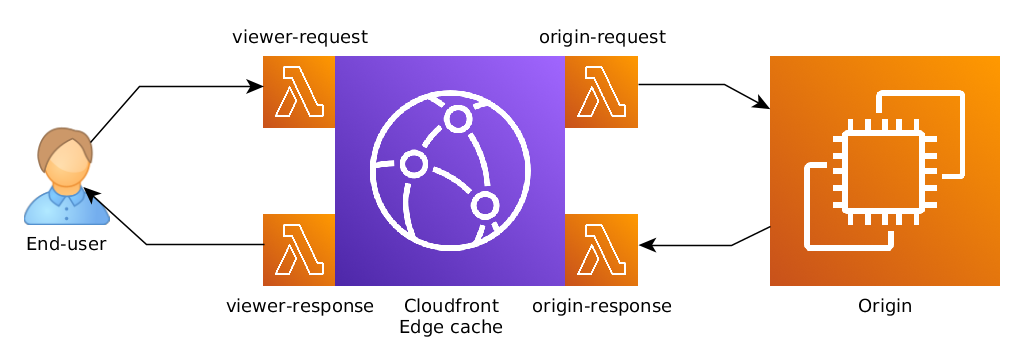
- Use Cases:
- Website Security and Privacy
- Dynamic Web Application at the Edge
- Search Engine Optimization (SEO)
- Intelligently Route Across Origins and Data Centers
- Bot Mitigation at the Edge
- Real-time Image Transformation
- A/B Testing
- User Authentication and Authorization
- User Prioritization
- User Tracking and Analytics
S3 Transfer Acceleration
Increase transfer speed by transferring file to an AWS edge location which will forward the data to the S3 bucket in the target region
AWS Global Accelerator
- Improve global application availability and performance using the AWS global network
- Leverage the AWS internal network to optimize the route to your application (60% improvement)
- 2 Anycast IP are created for your application and traffic is sent through Edge Locations
- The Edge locations send the traffic to your application
Tip
- Unicast IP: one server holds one IP address
- Anycast IP: all servers hold the same IP address and the client is routed to the nearest one
- Works with Elastic IP, EC2 instances, ALB, NLB, public or private
- Consistent Performance
- Intelligent routing to lowest latency and fast regional failover
- No issue with client cache (because the IP doesn’t change)
- Internal AWS network
- Health Checks
- Global Accelerator performs a health check of your applications
- Helps make your application global (failover less than 1 minute for unhealthy)
- Great for disaster recovery (thanks to the health checks)
- Security
- only 2 external IP need to be whitelisted
- DDoS protection thanks to AWS Shield
AWS Global Accelerator vs CloudFront
- They both use the AWS global network and its edge locations around the world
- Both services integrate with AWS Shield for DDoS protection.
- Improves performance for your cacheable content (such as images and videos)
- Dynamic content(such as API acceleration and dynamic site delivery)
- Content is served at the edge
- Improves performance for a wide range of applications over TCP or UDP
- No caching, proxying packets at the edge to applications running in one or more AWS Regions
- Good fit for non-HTTP use cases, such as gaming(UDP), IoT(MQTT),or Voice over IP
- Good for HTTP use cases that require static IP addresses, deterministic, fast regional failover
AWS Outposts
- Hybrid Cloud: businesses that keep an on-premises infrastructure alongside a cloud infrastructure
- Therefore, two ways of dealing with IT systems:
- One for the AWS cloud (using the AWS console, CLI, and AWS APIs)
- One for their on-premises infrastructure
- AWS Outposts are "server racks" that offers the same AWS infrastructure, services, APIs & tools to build your own applications on-premises just as in the cloud
- AWS will setup and manage "Outposts Racks" within your on-premises infrastructure and you can start leveraging AWS services on-premises
- You are responsible for the Outposts Rack physical security
- Benefits:
- Low-latency access to on-premises systems
- Local data processing
- Data residency
- Easier migration from on-premises to the cloud
- Fully managed service
AWS WaveLength
WaveLength Zones are infrastructure deployments embedded within the telecommunications providers’ datacenters at the edge of the 5G networks
- Brings AWS services to the edge of the 5G networks (Example:EC2,EBS,VPC...)
- Ultra-low latency applications through 5G networks
- Traffic doesn’t leave the Communication Service Provider’s (CSP) network
- High-bandwidth and secure connection to the parent AWS Region
- No additional charges or service agreements
- Use cases:
- Smart Cities
- ML-assisted diagnostics
- Connected Vehicles
- Interactive Live Video Streams
- AR/VR
- Real-time Gaming
- ...
AWS Local Zones
- Places AWS compute, storage, database, and other selected AWS services closer to end users to run latency-sensitive applications
- Extend your VPC to more locations – "Extension of an AWS Region"
- Compatible with EC2, RDS, ECS, EBS, ElastiCache, Direct Connect ...
VPC
A VPC is a logically isolated, software-defined portion of the AWS cloud within a region
Note
- CIDR block size can be between /16 and /28
- The CIDR block must not overlap with any existing CIDR block that's associated with the VPC
- You cannot increase or decrease the size of an existing CIDR block, but you can add a secondary CIDR block to an existing VPC
Tip
CIDR stands for Classless Inter-Domain Routing
Subnet(IPv4)
- AWS reserves 5 IP addresses (first 4 & last 1) in each subnet
- These 5 IP addresses are not available for use and can’t be assigned to an EC2 instance
Example
if CIDR block 10.0.0.0/24, then reserved IP addresses are:
- 10.0.0.0 – Network Address
- 10.0.0.1 – reserved by AWS for the VPC router
- 10.0.0.2 – reserved by AWS for mapping to Amazon-provided DNS
- 10.0.0.3 – reserved by AWS for future use
- 10.0.0.255 – Network Broadcast Address. AWS does not support broadcast in a VPC, therefore the address is reserved
VPC & Subnets Primer
- VPC - Virtual Private Cloud: private network to deploy your resources (regional resource)
- Subnets allow you to partition your network inside your VPC (Availability Zone resource)
- A public subnet is a subnet that is accessible from the internet
- A private subnet is a subnet that is not accessible from the internet
- To define access to the internet and between subnets, we use Route Tables.
Internet Gateway
- Allows resources (e.g., EC2 instances) in a VPC connect to the Internet
- It scales horizontally and is highly available and redundant
- Must be created separately from a VPC
- One VPC can only be attached to one IGW and vice versa
Tip
Internet Gateways on their own do not allow Internet access... -> Route tables must also be edited! IPv6 only (egress) : Internet Gateway IPv4 only (ingress) : NAT Gateway
Bastion Hosts
- We can use a Bastion Host to SSH into our private EC2 instances
- The bastion is in the public subnet which is then connected to all other private subnets
- Bastion Host security group must allow inbound from the internet on port 22 from restricted CIDR
- Security Group of the EC2 Instances must allow the Security Group of the Bastion Host, or the private IP of the Bastion host
NAT Instance
NAT = Network Address Translation
- Allows EC2 instances in private subnets to connect to the Internet
- Must be launched in a public subnet
- Must disable EC2 setting:
Source/destinationCheck - Must have Elastic IP attached to it
- RouteTables must be configured to route traffic from private subnets to the NAT Instance
NAT Gateway
AWS-managed NAT, higher bandwidth, high availability, no administration
- Pay per hour for usage and bandwidth
- NATGW is created in a specific Availability Zone, uses an Elastic IP
- Can’t be used by EC2 instance in the same subnet (only from other subnets)
- Requires an IGW (Private Subnet => NATGW => IGW)
- 5 Gbps of bandwidth with automatic scaling up to 45 Gbps
- No Security Groups to manage / required
Tip
Ensure that your connection is using a TCP, UDP, or ICMP protocol only.
Network Access Control List(NACL)
NACL are like a firewall which control traffic from and to subnets
- One NACL per subnet, new subnets are assigned the Default NACL
- You define NACL Rules:
- Rules have a number (1-32766), higher precedence with a lower number
- First rule match will drive the decision
- The last rule is an asterisk (*) and denies a request in case of no rule match
- AWS recommends adding rules by increment of 100
- Newly created NACLs will deny everything
- NACL are a great way of blocking a specific IP address at the subnet level
Default NACL
- Accepts everything inbound/outbound with the subnets it’s associated with
- Do NOT modify the Default NACL, instead create custom NACLs
Ephemeral Ports
- For any two endpoints to establish a connection, they must use ports
- Clients connect to a defined port, and expect a response on an ephemeral port
- Different Operating Systems use different port ranges, examples:
- IANA & MS Windows10 -> 49152–65535
- Many Linux Kernel -> 32768–60999
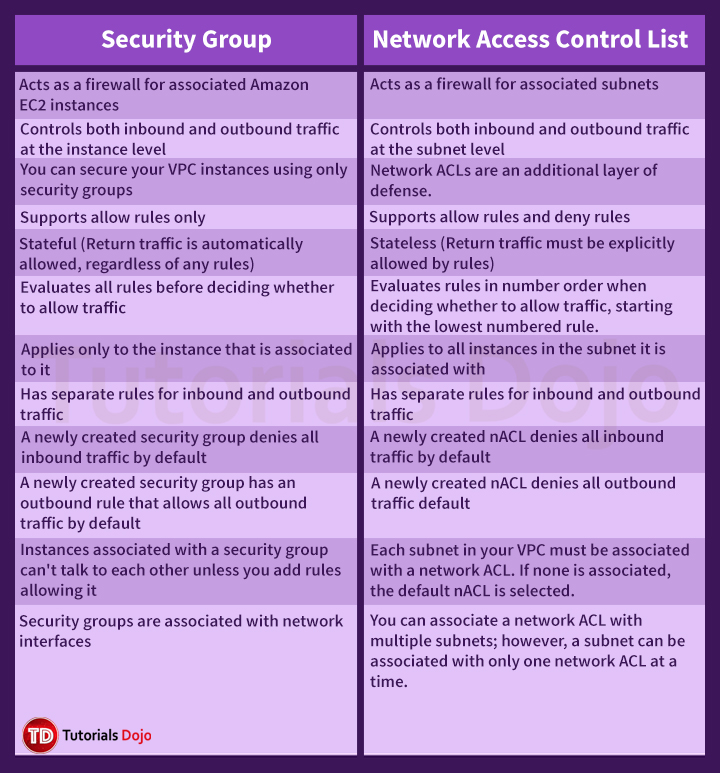
Network ACL VS Security Groups
- A firewall that controls traffic to and from an ENI(Elastic Network Interface) / an EC2 Instance
- Can have only ALLOW rules
- Is stateful: Return traffic is automatically allowed, regradless of any rules
- All rules evaluated before deciding whether to allow traffic
- Applies to an instance only if someone specifies the security when launching the instance or associate the security group with the instance later on
- Rules include IP addresses and other security groups
- Security Groups can be applied to instances in any subnet
- A firewall which controls traffic from and to subnet
- Can have ALLOW and DENY rules
- Is stateless: Return traffic must be explicitly allowed by rules
- Rules processed in number order when deciding whether to allow traffic
- Are attached at the Subnet level
- Rules only include IP addresses
Tip
- A stateful firewall allows the return traffic automatically
- A stateless firewall checks for an allow rule for both connections
VPC Flow Logs

Capture information about the IP traffic flowing in or out of network interfaces in a VPC:
- VPC Flow Logs
- Subnet Flow Logs
- Elastic Network Interface Flow Logs
- Helps to monitor & troubleshoot connectivity issues
- Example:
- Subnets to internet
- Subnets to subnets
- Internet to subnets
- Captures network information from AWS managed interfaces too: Elastic Load Balancers, ElastiCache, RDS, Aurora, etc...
- VPC Flow logs data can go to S3 bucket / CloudWatch Logs
- Flow logs can be created at the following levels:
- VPC
- Subnet
- Network interface
Tip
Flow logs do not provide the ability to view a real-time stream of traffic. Logs are published every 10 minutes by default but can be configured for faster delivery.
Warning
After you create a flow log, you CANNOT change its configuration or the flow log record format
VPC to VPC Connectivity Options
- VPC Peering
- AWS Transit Gateway
- Software S2S VPN
- Software VPN to AWS VPN
- AWS Managed VPN
- AWS PrivateLink
VPC Peering
Connect two VPC, privately using AWS’s network
- Make them behave as if they were in the same network
- Must not have overlapping CIDR (IP address range)
- VPC Peering connection is not transitive (must be established for each VPC that need to communicate with one another)
- You must update route tables in each VPC’s subnets to ensure EC2 instances can communicate with each other
- VPC Peering enables routing using private IPv4 or IPv6 addresses
Tip
- You can create VPC Peering connection between VPCs in different AWS accounts/regions
- You can reference a security group in a peeredVPC (works cross accounts – same region)
- You cannot reference the security group of a peer VPC that's in a different Region. Instead, use the CIDR block of the peer VPC
- BGP protocol uses TCP port 179 for establishing a peering connection. While establishing AWS VPN connectivity using BGP protocol, it needs to be checked that TCP port 179 is not blocked in the network
VPC Endpoints
VPC Endpoints (powered by AWS PrivateLink) allow resources inside a VPC to connect to other AWS Services outside the VPC using a private network instead of the public www network
- Gives you enhanced security and lower latency to access AWS services
- Redundant and scale horizontally
- Remove the need of IGW, NATGW, ... to access AWS Services
- VPC Endpoint Gateway: S3 & DynamoDB
- VPC Endpoint Interface: the rest
- Only used within your VPC
Types of Endpoints
- An ENI within an AWS VPC that has a private IP address within the VPC subnet of the resources that are consuming the service
- Provisions an ENI (private IP address) as an entry point (must attach a Security Group)
- Uses DNS entries to redirect traffic
- Supports most AWS services(API Gateway, CloudFormation, CloudWatch etc.)
- Security: Security Groups
- $ per hour + $ per GB of data processed
- Provisions a gateway and must be used as a target in a route table (does not use security groups)
- Uses prefix lists in the route table to redirect traffic
- Supports both S3 and DynamoDB
- Security: VPC Endpoint Policies
- Free
Site to Site VPN & Direct Connect
- AWS VPN is a managed IPSec VPN
- Connect an on-premises VPN to AWS
- The connection is automatically encrypted
- Supports static routes or BGP peering/routing
- Goes over the public internet
- A VGW(Virtual Private Gateway) is deployed on the AWS site
- A CGW(Customer Gateway) is deployed on the customer side
- DX is a physical fibre connection between on-premises and AWS running at 1Gbps or 10Gbps or 100Gbps
- A cross-connect between the AWS DX router and the customer/partner DX router
- A DX port (1000-Base-LX or 10GBASE-LR) must be allocated in a DX location
- The customer router is connected to the DX router in the DX location
- The connection is private, secure and fast
- Goes over a private network
- Takes at least a month to establish
- Speeds from 50Mbps to 500Mbps can also be accessed via an APN partner
- DX Connections are NOT encrypted!
- Use an
IPSec S2S VPNconnection over a VIF to add encryption in transit
Note
Site-to-site VPN and Direct Connect cannot access VPC endpoints
Note
- A VIF is a virtual interface (802.1Q VLAN) and a BGPsession
- A Private VIF connects to a single VPC in the same AWS Region using a VGW
- A Public VIF can be used to connect to AWS Public services in any Region (but not the Internet)
- Multiple Private VIFs can be used to connect to multiple VPCs in the Region
- VIFs can also be shared with other AWS accounts – known as hosted VIFs
AWS VPN CloudHub
- A VGW is deployed on the AWS site
- Network traffic may go between a VPC and a remote office
- Network traffic between offices can also be routed over the IPSec VPN
- Remote offices connect to the VGW in a hub-and-spoke mode
- Each office must use a unique BGP ASN
Transit Gateway
Transit Gateway is a network transit hub that interconnects VPCs and on-premises networks
- For having transitive peering between thousands of VPC and on-premises, hub-and-spoke (star) connection
- One single Gateway to provide this functionality
- TGWs can be attached to VPNs, Direct Connect Gateways, 3rd party appliances and TGWs in other Regions/accounts
Note
Connections supported by a transit gateway:
- VPN to a physical datacenter
- Direct Connect Gateway
- Transitive connections between multiple VPCs
Tip
- VPC Peering does not have an aggregate bandwidth limitation.
- Transit gateway connections to a VPC provide up to 50 Gbps of bandwidth.
- A VPN connection provides a maximum throughput of 1.25 Gbps.
IPv6 in VPC
- IPv4 cannot be disabled for your VPC and subnets
- All IPv6 addresses are publicly routable (no NAT)
- You can enable IPv6 (they’re public IP addresses) to operate in dual-stack mode
- Your EC2 instances will get at least a private internal IPv4 and a public IPv6
- They can communicate using either IPv4 or IPv6 to the internet through an Internet Gateway
Egress-only Internet Gateway
- Used for IPv6 only(similar to a NAT Gateway but for IPv6)
- Allows instances in your VPC outbound connections over IPv6 while preventing the internet to initiate an IPv6 connection to your instances
- You must update the Route Tables
AWS Network Firewall
- The AWS Network Firewall supports outbound traffic control using HTTPS (SNI)/HTTP protocol URL filtering, access control lists (ACLs), DNS queries, and protocol detection.
- AWS Network Firewall rules can be based on domain, port, protocol, IP addresses, and pattern matching.
Traffic Mirroring
- VPC Traffic Mirroring duplicates inbound and outbound traffic for Amazon EC2 instances within an Amazon VPC without the need to install anything on the instances themselves.
- You are able to send the duplicated traffic to the destination of your choice for analysis.
- VPC Traffic Mirroring collects the full packet, allowing payload analysis, while other tools collect information of protocol, source, and destination. This lets you analyze for both active and passive attacks.
Tip
The following traffic types cannot be mirrored:
- ARP
- DHCP
- Instance metadata service
- NTP
- Windows activation
Gateway
AWS Storage Gateway
AWS Storage Gateway is a service that connects an on-premises data center to the cloud. It provides block-based storage that is compatible with the Portable Operating System Interface (POSIX) and can be used as a target for data backups
Tip
To use the HA feature of Storage Gateway, the VMware environment must provide the following:
- A cluster with vSphere HA enabled
- A shared datastore
File Gateway
- File gateway provides a virtual on-premises file server
- Store and retrieve files as objects in Amazon S3
- Use with on-premises applications, and EC2-based applications that need file storage in S3 for object-based workloads
- File gateway offers SMB or NFS-based access to data in Amazon S3 with local caching
- A local cache provides low latency access to recently used data
- A virtual gateway appliance runs on Hyper-V, VMware, or EC2
Tip
CachePercentDirty is an Amazon CloudWatch metric for Amazon S3 File Gateway which provides a percentage of the data not uploaded to AWS from local Cache. This metric value should be near to zero to ensure all cache data is properly uploaded to AWS.
Volume Gateway
- The volume gateway supports block-based volumes
- Block storage – iSCSI protocol
- Cached Volume mode – the entire dataset is stored on S3 and a cache of the most frequently accessed data is cached on-site
- Stored Volume mode – the entire dataset is stored on-site and is asynchronously backed up to S3 (EBS point-in-time snapshots). Snapshots are incremental and compressed
Tape Gateway
- Used for backup with popular backup software
- Each gateway is preconfigured with a media changer and tape drives. Supported by NetBackup, Backup Exec, Veeam etc.
- When creating virtual tapes, you select one of the following sizes: 100 GB, 200 GB, 400 GB, 800 GB, 1.5 TB, and 2.5 TB
- A tape gateway can have up to 1,500 virtual tapes with a maximum aggregate capacity of 1 PB
- All data transferred between the gateway and AWS storage is encrypted using SSL
- All data stored by tape gateway in S3 is encrypted server-side with Amazon S3-Managed Encryption Keys (SSE-S3)
S3
Use Cases
- Backup and storage
- Disaster Recovery
- Archive
- Hybrid Cloud storage
- Application hosting
- Media hosting
- Data lakes & big data analytics
- Software delivery
- Static website
Buckets
- Amazon S3 allows people to store objects (files) in "buckets" (directories)
- Buckets must have a globally unique name (across all regions all accounts)
- Buckets are defined at the region level
- S3 looks like a global service but buckets are created in a region
- Naming convention
- Can consist only of lowercase letters, numbers, dots (.), and hyphens (-)
- 3-63 characters long
- Not an IP
- Must start with lowercase letter or number
- Must NOT start with the prefix
xn-- - Must NOT end with the suffix
-s3alias(This suffix is reserved for access point alias names) - Must not end with the suffix
--ol-s3(This suffix is reserved for Object Lambda Access Point alias names)
Objects
- Objects (files) have a
Key(The object name is the Key, the data is the Value)- The key is the FULL path
- A Folder is a
shared prefixfor grouping objects - The key is composed of prefix + object name
- Just keys with very long names that contain slashes ("/")
- Object
Valuesare the content of the body Tags(Unicode key / value pair – up to 10) – useful for security / lifecycle
Note
An objects consists of:
- Key (the name of the object)
- Version ID (if versioning is enabled)
- Value (actual data)
- Metadata (list of text key / value pairs – system or user metadata)
- Subresources
- Access control information
Tip
- Folders can be created within folders
- Buckets cannot be created within buckets
Multipart Upload
- Multipart upload uploads objects in parts independently, in parallel and in any order
- Performed using the S3 Multipart upload API
- It is recommended for objects of 100 MB or larger
- Can be used for objects from 5 MB up to 5 TB
- Must be used for objects larger than 5 GB
Tip
It's a best practice to use aws s3 commands (such as aws s3 cp) for multipart uploads and downloads, because these aws s3 commands automatically perform multipart uploading and downloading based on the file size.
By comparison, aws s3api commands, such as aws s3api create-multipart-upload, should be used only when aws s3 commands don't support a specific upload need. Such as when the multipart upload involves multiple servers, a multipart upload is manually stopped and resumed later, or when the aws s3 command doesn't support a required request parameter.
Note
Content-MD5 header is an optional header in the Amazon S3 REST requests, which can be used to check the integrity of the data and ensure data is not corrupt during transit.
When data is uploaded using PutObject having Content-MD5 as a request header, Amazon S3 checks the data against the Content-MD5 value. If the value is not matched, an error is generated.
Versioning
Versioning is a means of keeping multiple variants of an object in the same bucket
- Use versioning to preserve, retrieve, and restore every version of every object stored in your Amazon S3 bucket
- Versioning-enabled buckets enable you to recover objects from accidental deletion or overwrite
- It is enabled at the bucket level
- Same key overwrite will increment the "version": 1, 2, 3....
- It is best practice to version your buckets
- Protect against unintended deletes (ability to restore a version)
- Easy roll back to previous version
Notes
- Any file that is not versioned prior to enabling versioning will have version "null"
- Suspending versioning does not delete the previous versions
Security
- User based
IAM policies- which API calls should be allowed for a specific user from IAM console
- Resource Based
Bucket Policies- bucket wide rules from the S3 console - allows cross accountObject Access Control List (ACL)– finer grain(can be disabled)Bucket Access Control List (ACL)– less common(can be disabled)
Note
An IAM principal can access an S3 object if
- the user IAM permissions allow it OR the resource policy ALLOWS it
- AND there’s no explicit DENY
- Encryption: encrypt objects in Amazon S3 using encryption keys
- Networking:
- Supports VPC Endpoints (for instances inVPC without www internet)
- Logging and Audit:
- S3 Access Logs can be stored in other S3 bucket
- API calls can be logged in AWS CloudTrail
- User Security:
- MFA Delete: MFA (multi factor authentication) can be required in versioned buckets to delete objects
- Pre-Signed URLs: URLs that are valid only for a limited time (ex: premium video service for logged in users)
Tip
AWS generally recommends using S3 bucket policies or IAM policies rather than ACLs
S3 Bucket Policies
- JSON based policies
- Resources: buckets and objects
- Effect: Allow / Deny
- Actions: Set of API to Allow or Deny
- Principal:The account or user to apply the policy to
- Use S3 bucket for policy to:
- Grant public access to the bucket
- Force objects to be encrypted at upload
- Grant access to another account (Cross Account)
IAM Policy VS S3 Bucket Policy
- You need to control access to AWS services other than S3
- You have numerous S3 buckets each with different permissions requirements (IAM policies will be easier to manage)
- You prefer to keep access control policies in the IAM environment
- You want a simple way to grant cross-account access to your S3 environment, without using IAM roles
- Your IAM policies are reaching the size limits
- You prefer to keep access control policies in the S3 environment
Objects Encryption
There are 4 methods of encrypting objects in S3
- Server-Side Encryption with Amazon S3-Managed Keys
- Encrypts S3 objects using keys handled & managed by AWS
- Object is encrypted server side
- AES-256 encryption type
- Must set header:
"x-amz-server-side-encryption": "AES256"
- Server-Side Encryption with KMS Keys stored in AWS KMS
- Leverage
AWS Key ManagementService to manage encryption keys - KMS Advantages: user control + audit key usage using CloudTrail
- Object is encrypted server side
- Must set header:
"x-amz-server-side-encryption": "aws:kms"
- Server-Side Encryption with Customer-Provided Keys
- Server-side encryption using data keys fully managed by the customer outside of AWS
- Amazon S3 does not store the encryption key you provide
- HTTPS must be used
- Encryption key must provided in HTTP headers, for every HTTP request made
- Use Client library such as the Amazon S3 Client-Side Encryption Library
- Clients must encrypt data themselves before sending to S3
- Clients must decrypt data themselves when retrieving from S3
- Customer fully manages the keys and encryption cycle
Default Encryption
- Amazon S3 default encryption provides a way to set the default encryption behavior for an S3 bucket
- You can set default encryption on a bucket so that all new objects are encrypted when they are stored in the bucket
- The objects are encrypted using server-side encryption
- Amazon S3 encrypts objects before saving them to disk and decrypts them when the objects are downloaded
- There is no change to the encryption of objects that existed in the bucket before default encryption was enabled
Encryption in transit (SSL/TLS)
Encryption in flight is also called SSL/TLS
- Amazon S3 exposes:
- HTTP endpoint: non encrypted
- HTTPS endpoint: encryption in flight
- You’re free to use the endpoint you want, but HTTPS is recommended
- Most clients would use the HTTPS endpoint by default
- HTTPS is mandatory for SSE-C
- Encryption in flight is also called SSL /TLS
MFA Delete(Multi-Factor Authentication Delete)
- Adds MFA requirement for bucket owners to the following operations:
- Changing the versioning state of a bucket
- Permanently deleting an object version
- The
x-amz-mfarequest header must be included in the above requests - The second factor is a token generated by a hardware device or software program
- Requires versioning to be enabled on the bucket
Tip
- Versioning can be enabled by:
- Bucket owners (root account)
- AWS account that created the bucket
- Authorized IAM users
- MFA delete can be enabled by:
- Bucket owner (root account)
S3 Event Notifications
- Sends notifications when events happen in buckets
- Destinations include:
- Amazon Simple Notification Service (SNS) topics
- Amazon Simple Queue Service (SQS) queues
- AWS Lambda
Server Access Logging
- Provides detailed records for the requests that are made to a bucket
- Details includes:
- requester
- bucket name
- request time
- request action
- response status
- error code (if applicable)
- Disabled by default
- Only pay for the storage space used
- Must configure a separate bucket as the destination (can specify a prefix)
- Must grant write permissions to the Amazon S3 Log Delivery group on destination bucket
Static Websites Hosting
- S3 can host static websites and have them accessible on the www
- The website URL will be:
http://<bucket-name>.s3-website-<AWS-region>.amazonaws.comhttp://<bucket-name>.s3-website.<AWS-region>.amazonaws.com
- If you get a 403 (Forbidden) error, make sure the bucket policy allows public reads!
- If a client does a cross-origin request on our S3 bucket, we need to enable the correct CORS headers
Replication(CRR & SRR)
- Must enable versioning in source and destination
- Must give proper IAM permissions to S3
- Buckets can be in different accounts
- Copying is asynchronous
- Use Cases:
- Cross Region Replication (CRR): compliance, lower latency access, replication across accounts
- Same Region Replication (SRR): log aggregation, live replication between production and test accounts
Note
- After you enable Replication, only new objects are replicated
- Optionally, you can replicate existing objects using S3 Batch Replication
- Replicates existing objects and objects that failed replication
- For DELETE operations
- Can replicate delete markers from source to target (optional setting)
- Deletions with a version ID are not replicated (to avoid malicious deletes)
- There is no "chaining" of replication
- If bucket 1 has replication into bucket 2, which has replication into bucket 3
- Then objects created in bucket 1 are not replicated to bucket 3
S3 Pre-Signed URLs
- Can generate pre-signed URLs using SDK or CLI
- For downloads (easy, can use the CLI)
- For uploads (harder, must use the SDK)
- Valid for a default of 3600 seconds, can change timeout with
--expires-in <TIME_BY_SECONDS>argument - Users given a pre-signed URL inherit the permissions of the person who generated the URL for GET / PUT
CORS with Amazon S3
Allows requests from an origin to another origin
Origin is defined by DNS name, protocol, and port
- Enabled through setting:
- Access-Control-Allow-Origin
- Access-Control-Allow-Methods
- Access-Control-Allow-Headers
- These settings are defined using rules
- Rules are added using JSON files in S3
Cross Account Access
Methods:
- Resource-based policies and IAM policies for programmatic-only access to S3 bucket objects
- Resource-based ACL and IAM policies for programmatic-only access to S3 bucket objects
- Cross-account IAM roles for programmatic and console access to S3 bucket objects
Storage Classes
- General Purpose
- Infrequent Access
- Standard-Infrequent Access (IA)
- 99.9% Availability
- Use cases: Disaster Recovery, backups
- One Zone-Infrequent Access
- High durability (99.999999999%) in a single AZ; data lost when AZ is destroyed
- 99.5% Availability
- Use Cases: Storing secondary backup copies of on-premises data, or data you can recreate
- Standard-Infrequent Access (IA)
- Glacier Storage Classes
- Glacier Instant Retrieval
- Minimum storage duration of 90 days
- Millisecond retrieval, great for data accessed once a quarter
- Glacier Flexible Retrieval
- Minimum storage duration of 90 days
- Expedited (1 to 5 minutes)
- Standard (3 to 5 hours)
- Bulk (5 to 12 hours) – free
- Glacier Deep Archive
- Minimum storage duration of 180 days
- Standard (12 hours)
- Bulk (48 hours)
- Glacier Instant Retrieval
- Intelligent Tiering
- Small monthly monitoring and auto-tiering fee
- Moves objects automatically between Access Tiers based on usage
- There are no retrieval charges in S3 Intelligent-Tiering
- Frequent Access tier (automatic): default tier
- Infrequent Access tier (automatic): objects not accessed for 30 days
- Archive Instant Access tier (automatic): objects not accessed for 90 days
- Archive Access tier (optional): configurable from 90 days to 700+ days
- Deep Archive Access tier (optional): config. from 180 days to 700+ days
Note
Can move between classes manually or using S3 Lifecycle configurations
Lifecycle Rules
TransitionActions – configure objects to transition to another storage class- Move objects to Standard IA class 60 days after creation
- Move to Glacier for archiving after 6 months
Expirationactions – configure objects to expire (delete) after some time- Access log files can be set to delete after a 365 days
- Can be used to delete old versions of files (if versioning is enabled)
- Can be used to delete incomplete Multi-Part uploads
- Rules can be created for a certain prefix (example: s3://mybucket/mp3/*)
- Rules can be created for certain objectsTags (example:Department:Finance)

Select & Glacier Select
- Retrieve less data using SQL by performing server-side filtering
- Can filter by rows & columns (simple SQL statements)
- Less network transfer, less CPU cost client-side
S3 Batch Operations
- Perform bulk operations on existing S3 objects with a single request, example:
- Modify object metadata & properties
- Copy objects between S3 buckets
- Encrypt un-encrypted objects
- Modify ACLs,tags
- Restore objects from S3 Glacier
- Invoke Lambda function to perform custom action on each object
- A job consists of a list of objects, the action to perform, and optional parameters
- S3 Batch Operations manages retries, tracks progress, sends completion notifications, generate reports ...
- You can use S3 Inventory to get object list and use S3 Select to filter your objects
Pre-Signed URLs
- Generate pre-signed URLs using the S3 Console, AWS CLI or SDK
- URL Expiration
- S3 Console – 1 min up to 720 mins (12 hours)
- AWS CLI – configure expiration with
--expires-inparameter in seconds (default 3600 secs, max. 604800 secs ~ 168 hours)
- Users given a pre-signed URL inherit the permissions of the user that generated the URL for GET / PUT
Example
- Allow only logged-in users to download a premium video from your S3 bucket
- Allow an ever-changing list of users to download files by generating URLs dynamically
- Allow temporarily a user to upload a file to a precise location in your S3 bucket
S3 Object Lock & Glacier Vault Lock
- Adopt a WORM (Write Once Read Many) model
- Block an object version deletion for a specified amount of time
- Retention mode - Compliance:
- Object versions can't be overwritten or deleted by any user, including the root user
- Objects retention modes can't be changed, and retention periods can't be shortened
- Retention mode - Governance:
- Most users can't overwrite or delete an object version or alter its lock settings
- Some users have special permissions to change the retention or delete the object
- Retention Period: protect the object for a fixed period, it can be extended
- Legal Hold:
- Protect the object indefinitely, independent from retention period
- Can be freely placed and removed using the
s3:PutObjectLegalHoldIAM permission
- Adopt a WORM (Write Once Read Many) model
- Create a Vault Lock Policy
- Lock the policy for future edits (can no longer be changed)
- Helpful for compliance and data retention
- Locking a vault takes two steps:
- Initiate the lock by attaching a Vault Lock policy to your vault, which sets the lock to an in-progress state and returns a lock ID.
- While the policy is in the in-progress state, you have 24 hours to validate your Vault Lock policy before the lock ID expires.
- To prevent your vault from exiting the in-progress state, you must complete the Vault Lock process within these 24 hours. Otherwise, your Vault Lock policy will be deleted.
- Use the lock ID to complete the lock process. If the Vault Lock policy doesn't work as expected, you can stop the Vault Lock process and restart from the beginning.
- Initiate the lock by attaching a Vault Lock policy to your vault, which sets the lock to an in-progress state and returns a lock ID.
Warning
- After you enable Object Lock on a bucket, you can't disable Object Lock or suspend versioning for that bucket.
- S3 buckets with Object Lock can't be used as destination buckets for server access logs.
Access Points & Object Lambda
- Each Access Point gets its own DNS and policy to limit who can access it
- A specific IAM user / group
- One policy per Access Point => Easier to manage than complex bucket policies
- Use AWS Lambda Functions to change the object before it is retrieved by the caller application
- You can use your own functions or use the AWS pre-built functions
- Only one S3 bucket is needed, on top of which we create S3 Access Point and S3 Object Lambda Access Points.
- Use Cases:
- Redacting personally identifiable information for analytics or non- production environments.
- Converting across data formats,such as converting XML to JSON.
- Resizing and watermarking images on the fly using caller-specific details, such as the user who requested the object.
AWS Storage Gateway
- Bridge between on-premise data and cloud data in S3
- Hybrid storage service to allow on-premises to seamlessly use the AWS Cloud
- Use cases:
- disaster recovery
- backup & restore
- tiered storage
- on-premises cache & low-latency files access
- Types of Storage Gateway:
- S3 File Gateway
- FSx File Gateway
- Volume Gateway
- Tape Gateway
Container
Docker Containers Management on AWS
- Amazon Elastic Container Service (Amazon ECS)
- Amazon’s own container platform
- Amazon Elastic Kubernetes Service (Amazon EKS)
- Amazon’s managed Kubernetes (open source)
- AWS Fargate
- Amazon’s own Serverless container platform
- Works with ECS and with EKS
- Amazon ECR:
- Store container images
ECS
ECS: Elastic Container Service
Note
ECS Key Concepts:
- Task Definition: Templates for your tasks. This is where you sepcify your Docker image, Memory, CPU, Ports, Volumes, Environment Variables, etc.
- Task: A running instance of a Task Definition
- Container(EC2 only): Virtualized Instance that run your Tasks
- Cluster
- EC2 Launch Type: A cluster of EC2 instances that run your Tasks
- Fargate Launch Type: A cluster of Fargate Tasks
- Service: A Task management system that ensures X amount of tasks are up and running at all times
EC2 Launch Type
- Launch Docker containers on AWS = Launch ECS Tasks on ECS Clusters
- You must provision & maintain the infrastructure (the EC2 instances)
- Each EC2 Instance must run the ECS Agent to register in the ECS Cluster
- AWS takes care of starting / stopping containers
- Has integrations with the Application Load Balancer
- Charged per running EC2 instance
- Docker volumes, EFS, and FSx for Windows File Server
- You handle cluster optimization
- More granular control over infrastructure
Fargate LaunchType
- You do not provision the infrastructure (no EC2 instances to manage)
- It’s all Serverless! You just create task definitions
- AWS just runs ECS Tasks for you based on the CPU / RAM you need
- To scale, just increase the number of tasks
- Charged for running tasks
- EFS integration
- Fargate handles cluster optimization
- Limited control, infrastructure is automated
IAM Roles for ECS
- Used by the ECS agent
- Makes API calls to ECS service
- Send container logs to CloudWatch Logs
- Pull Docker image from ECR
- Reference sensitive data in Secrets Manager or SSM Parameter Store
- Allows each task to have a specific role -> provide permissions to the container
- Use different roles for the different ECS Services you run
- Task Role is defined in the task definition
Note
Container instances have access to all of the permissions that are supplied to the container instance role through instance metadata
Load Balancer Integrations
Application Load Balancersupported and works for most use casesNetwork Load Balancerrecommended only for high throughput / high performance use cases, or to pair it with AWS Private Link- Elastic Load Balancer supported but not recommended (no advanced features – no Fargate)
Data Volumes (EFS)
- Mount EFS file systems onto ECS tasks
- Works for both EC2 and Fargate launch types
- Tasks running in any AZ will share the same data in the EFS file system
- Fargate + EFS = Serverless
- Use cases: persistent multi-AZ shared storage for your containers
- Note: Amazon S3 cannot be mounted as a file system
Data Volumes (Bind Mounts)
- Share data between multiple containers in the same Task Definition
- Works for both EC2 and Fargate tasks
- EC2 Tasks – using EC2 instance storage
- Data are tied to the lifecycle of the EC2 instance
- Fargate Tasks – using ephemeral storage
- Data are tied to the container(s) using them
- 20 GiB – 200 GiB (default 20 GiB)
- Use cases:
- Share ephemeral data between multiple containers
- "Sidecar" container pattern, where the "sidecar" container used to send metrics/logs to other destinations (separation of concerns)
ECS Service Auto Scaling
- Automatically increase/decrease the desired number of ECS tasks
- Amazon ECS Auto Scaling uses AWS Application Auto Scaling
- ECS Service Average CPU Utilization
- ECS Service Average Memory Utilization - Scale on RAM
- ALB Request Count Per Target – metric coming from the ALB
- Scaling Policies:
- Target Tracking – scale based on target value for a specific CloudWatch metric
- Step Scaling – scale based on a specified CloudWatch Alarm
- Scheduled Scaling – scale based on a specified date/time (predictable changes)
- ECS Service Auto Scaling (task level) ≠ EC2 Auto Scaling (EC2 instance level)
- Fargate Auto Scaling is much easier to setup (because Serverless)
Auto Scaling EC2 Instances
- Accommodate ECS Service Scaling by adding underlying EC2 Instances
- Auto Scaling Group Scaling
- Scale your ASG based on CPU Utilization
- Add EC2 instances over time
- ECS Cluster Capacity Provider
- Used to automatically provision and scale the infrastructure for your ECSTasks
- Capacity Provider paired with an Auto Scaling Group
- Add EC2 Instances when you’re missing capacity (CPU, RAM...)
Task Definitions
- Task definitions are metadata in JSON form to tell ECS how to run a Docker container
- It contains crucial information, such as:
- Image Name
- Port Binding for Container and Host
- Memory and CPU required
- Environment variables
- Networking information
- IAM Role
- Logging configuration (ex CloudWatch)
- Can define up to 10 containers in a Task Definition
Task Placement Strategies
- Binpack
- Tasks are placed on the least available amount of CPU and Memory
- Minimizes the number of EC2 instances in use (cost savings)
- Random
- Tasks are placed randomly
- Spread
- Tasks are placed evenly based on the specified value
- Example: instanceId, attribute:ecs.availability-zone, ...
Load Balancing (EC2 Launch Type)
- We get a Dynamic Host Port Mapping if you define only the container port in the task definition
- The ALB finds the right port on your EC2 Instances
- You must allow on the EC2 instance’s Security Group any port from the ALB’s Security Group
Load Balancing (Fargate)
- Each task has a unique private IP
- Only define the container port (host port is not applicable)
Example
- ECS ENI Security Group -> Allow port 80 from the ALB
- ALB Security Group -> Allow port 80/443 from web
Environment Variables
- Environment Variable
- Hardcoded – e.g., URLs
- SSM Parameter Store – sensitive variables (e.g., API keys, shared configs)
- Secrets Manager – sensitive variables (e.g., DB passwords)
- Environment Files (bulk) – Amazon S3
ECS Anywhere
- Run ECS or EKS on customer-managed infrastructure, supported by AWS
- Customers can run Amazon ECS/EKS Anywhere on their own on-premises infrastructure on bare metal servers
- You can also deploy ECS/EKS Anywhere using VMware vSphere
ECR
ECR: Elastic Container Registry
- Private and Public repository (Amazon ECR Public Gallery)
- This is where you store your Docker images so they can be run by ECS or Fargate
- Fully integrated with ECS and EKS
- Access is controlled through IAM (permission errors => policy)
- Supports image vulnerability scanning, versioning, image tags, image lifecycle, ...
- Supports Open Container Initiative (OCI) and Docker Registry HTTP API V2 standards
- You can use Docker tools and Docker CLI commands
- Can be accessed from any Docker environment – in the cloud, on-premises, or on you machine
- Container images and artifacts are stored in S3
- You can use namespaces to organize repositories
- Public repositories allow everyone to access container images
- Access control applies to private repositories:
- IAM access control - Set policies to define access to container images in private repositories
- Resource-based policies - Access control down to the individual API action
Note
Lifecycle policies- manage the lifecycle of the images in your repositoriesImage scanning- identify software vulnerabilities in your container imagesCross-Region and cross-account replication– replicate images across accounts/RegionPull through cache rules- cache repositories in remote public registries in your private Amazon ECR registry
EKS
EKS: Elastic Kubernetes Service
- Kubernetes is an open-source system for automatic deployment, scaling and management of containerized (usually Docker) application
- Kubernetes is cloud-agnostic (can be used in any cloud – Azure, GCP...)
- It is a way to launch managed Kubernetes clusters on AWS
- It’s an alternative to ECS, similar goal but different API
- EKS supports EC2 if you want to deploy worker nodes or Fargate to deploy serverless containers
- Use case: if your company is already using Kubernetes on-premises or in another cloud, and wants to migrate to AWS using Kubernetes
- For multiple regions, deploy one EKS cluster per region
- Collect logs and metrics using CloudWatch Container Insights
Tip
It is recommended to run Kubernetes Workloads on Amazon EC2 Spot Instances with Amazon EKS as a cost optimization practice.
Node Types
- Managed Node Groups
- Creates and manages Nodes (EC2 instances) for you
- Nodes are part of an ASG managed by EKS
- Supports On-Demand or Spot Instances
- Self-Managed Nodes
- Nodes created by you and registered to the EKS cluster and managed by an ASG
- You can use prebuilt AMI - Amazon EKS Optimized AMI
- Supports On-Demand or Spot Instances
- AWS Fargate
- No maintenance required
- no nodes managed
Data Volumes
- Need to specify StorageClass manifest on your EKS cluster
- Leverages a Container Storage Interface (CSI) compliant driver
- Support for...
- Amazon EBS
- Amazon EFS (works with Fargate)
- Amazon FSx for Lustre
- Amazon FSx for NetApp ONTAP
Auto Scaling
- Cluster Auto Scaling:
Vertical Pod Autoscaler- automatically adjusts the CPU and memory reservations for your pods to help "right size" your applicationsHorizontal Pod Autoscaler- automatically scales the number of pods in a deployment, replication controller, or replica set based on that resource's CPU utilization
- Workload Auto Scaling:
- Amazon EKS supports two autoscaling products:
- Kubernetes Cluster Autoscaler
- Karpenter open source autoscaling project
- The cluster autoscaler uses AWS scaling groups, while Karpenter works directly with the Amazon EC2 fleet
- Amazon EKS supports two autoscaling products:
App Runner
- Fully managed service that makes it easy to deploy containerized web applications and APIs at scale
- No infrastructure experience required
- Start with your source code or container image
- Automatically builds and deploy the web app
- Automatic scaling, highly available, load balancer, encryption
- VPC access support
- Connect to database, cache, and message queue services
- Use cases: web apps, APIs, microservices, rapid production deployments
Databases
Choosing the Right Database
Questions to choose the right database based on your architecture:
- Read-heavy, write-heavy, or balanced workload? Throughput needs? Will it change, does it need to scale or fluctuate during the day?
- How much data to store and for how long? Will it grow? Average object size? How are they accessed?
- Data durability? Source of truth for the data ?
- Latency requirements? Concurrent users?
- Data model? How will you query the data? Joins? Structured? Semi-Structured?
- Strong schema? More flexibility? Reporting? Search? RDBMS / NoSQL?
- License costs? Switch to Cloud Native DB such as Aurora?
Database Types
- RDBMS (= SQL / OLTP): RDS, Aurora – great for joins
- NoSQL database – no joins, no SQL
- DynamoDB (~JSON)
- ElastiCache (key / value pairs)
- Neptune (graphs)
- DocumentDB (for MongoDB)
- Keyspaces (for Apache Cassandra)
- Object Store
- S3 (for big objects)
- Glacier (for backups / archives)
- Data Warehouse (= SQL Analytics / BI)
- Redshift (OLAP)
- Athena
- EMR
- Search: OpenSearch (JSON) – free text, unstructured searches
- Graphs: Amazon Neptune – displays relationships between data
- Ledger: Amazon Quantum Ledger Database
- Time series: Amazon Timestream
- Note: some databases are being discussed in the Data & Analytics section
RDS
RDS stands for Relational Database Service
- It’s a managed DB service for DB use SQL as a query language.
- It allows you to create databases in the cloud that are managed by AWS
- Postgres
- MySQL
- MariaDB
- Oracle
- Microsoft SQL Server
- Aurora (AWS Proprietary database)
Note
RDS runs on EC2 instances, so you must choose an instance type
Advantage over using RDS versus deploying DB on EC2
- RDS is a managed service:
- Automated provisioning, OS patching
- Continuous backups and restore to specific timestamp (Point in Time Restore)!
- Monitoring dashboards
- Read replicas for improved read performance
- Multi AZ setup for DR (Disaster Recovery)
- Maintenance windows for upgrades
- Scaling capability (vertical and horizontal)
- Storage backed by EBS (gp2 or io1)
- BUT you can’t SSH into your instances
RDS Backups
- Backups are automatically enabled in RDS
- Automated backups:
- Daily full backup of the database (during the maintenance window)
- Transaction logs are backed-up by RDS every 5 minutes
- Ability to restore to any point in time (from oldest backup to 5 minutes ago)
- 7 days retention (can be increased to 35 days)
- Manual Backups (Snapshot):
- Manually triggered by the user
- Backs up the entire DB instance, not just individual databases
- For single-AZ DB instances there is a brief suspension of I/O
- For Multi-AZ SQL Server, I/O activity is briefly suspended on primary
- For Multi-AZ MariaDB, MySQL, Oracle and PostgreSQL the snapshot is taken from the standby
- Snapshots do not expire (no retention period)
Note
- The DB instance must be in the
availablestate for backups to occur - Restore can be to any point in time during the retention period
- Restored DB instances are associated with the default DB parameter and option groups
Maintenance Windows
- Operating system and DB patching can require taking the database offline
- These tasks take place during a maintenance window
- By default a weekly maintenance window is configured
- You can choose your own maintenance window
Storage Auto Scaling
- Helps you increase storage on your RDS DB instance dynamically
- When RDS detects you are running out of free database storage, it scales automatically
- Avoid manually scaling your database storage
- You have to set Maximum Storage Threshold (maximum limit for DB storage)
- Automatically modify storage if:
- Free storage is less than 10% of allocated storage
- Low-storage lasts at least 5 minutes
- 6 hours have passed since last modification
- Useful for applications with unpredictable workloads
- Supports all RDS database engines (MariaDB, MySQL, PostgreSQL, SQL Server, Oracle)
RDS Read Replicas for read scalability
- Up to 5 Read Replicas
- Within AZ, Cross AZ or Cross Region
- Replication is ASYNC, so reads are eventually consistent
- Replicas can be promoted to their own DB
- Applications must update the connection string to leverage read replicas
- Use Cases
- You have a production database that is taking on normal load
- You want to run a reporting application to run some analytics
- You create a Read Replica to run the new workload there
- The production application is unaffected
- Read replicas are used for SELECT (=read) only kind of statements (not INSERT, UPDATE, DELETE)
- Network cost
- In AWS there’s a network cost when data goes from one AZ to another
- For RDS Read Replicas within the same region, you don’t pay that fee
Tip
Read replicas can be used where the reads are frequently distributed across the majority of the data in the database
RDS Multi AZ (Disaster Recovery)
- SYNC replication
- One DNS name – automatic app failover to standby
- Increase availability
- Failover in case of loss of AZ, loss of network, instance or storage failure
- No manual intervention in apps
- Not used for scaling
- Multi-AZ replication is free
- Note:The Read Replicas be setup as Multi AZ for Disaster Recovery (DR)
RDS Custom
Managed Oracle and Microsoft SQL Server Database with OS and database customization
- RDS: Automates setup, operation, and scaling of database in AWS
- Custom: access to the underlying database and OS so you can
- Configure settings
- Install patches
- Enable native features
- Access the underlying EC2 Instance using SSH or SSM Session Manager
- De-activate Automation Mode to perform your customization, better to take a DB snapshot before
- RDS vs. RDS Custom
- RDS: entire database and the OS to be managed by AWS
- RDS Custom: full admin access to the underlying OS and the database
RDS Security - Encryption
- At rest encryption
- Possibility to encrypt the master & read replicas with AWS KMS - AES-256 encryption
- Encryption at rest can be enabled – includes DB storage, backups, read replicas and snapshots
- You can only enable encryption for an Amazon RDS DB instance when you create it, not after the DB instance is created
- DB instances that are encrypted can't be modified to disable encryption
- Uses AES 256 encryption and encryption is transparent with minimal performance impact
- If the master is not encrypted, the read replicas cannot be encrypted
- RDS for Oracle and SQL Server is also supported using Transparent Data Encryption (TDE) (may have performance impact)
- In-flight encryption
- SSL certificates to encrypt data to RDS in flight
- Provide SSL options with trust certificate when connecting to database
RDS Encryption Operations
- Encrypting RDS backups
- Snapshots of un-encrypted RDS databases are un-encrypted
- Snapshots of encrypted RDS databases are encrypted
- Can copy a snapshot into an encrypted one
- To encrypt an un-encrypted RDS database:
- Create a snapshot of the un-encrypted database
- Copy the snapshot and enable encryption for the snapshot
- Restore the database from the encrypted snapshot
- Migrate applications to the new database, and delete the old database
RDS Security – Network & IAM
- Network Security
- RDS databases are usually deployed within a private subnet, not in a public one
- RDS security works by leveraging security groups (the same concept as for EC2 instances) – it controls which IP / security group can communicate with RDS
- Access Management
- IAM policies help control who can manage AWS RDS (through the RDS API)
- Traditional Username and Password can be used to login into the database
- IAM-based authentication can be used to login into RDS MySQL & PostgreSQL
RDS Security – Summary
- Encryption at rest:
- Is done only when you first create the DB instance
- or: unencrypted DB => snapshot => copy snapshot as encrypted => create DB from snapshot
- Your responsibility:
- Check the ports / IP / security group inbound rules in DB’s SG
- In-database user creation and permissions or manage through IAM
- Creating a database with or without public access
- Ensure parameter groups or DB is configured to only allow SSL connections
- AWS responsibility:
- No SSH access
- No manual DB patching
- No manual OS patching
- No way to audit the underlying instance
RDS Proxy
- Fully managed database proxy for RDS
- Allows apps to pool and share DB connections established with the database
- Improving database efficiency by reducing the stress on database resources (e.g., CPU, RAM) and minimize open connections (and timeouts)
- Serverless, autoscaling, highly available (multi-AZ)
- Reduced RDS & Aurora failover time by up 66%
- Supports RDS (MySQL, PostgreSQL, MariaDB) and Aurora (MySQL, PostgreSQL)
- Enforce IAM Authentication for DB, and securely store credentials in AWS Secrets Manager
- RDS Proxy is never publicly accessible (must be accessed from VPC)
RDS Performance Insights
- Amazon RDS Performance Insights is a database performance tuning and monitoring feature that helps you quickly assess the load on your database, and determine when and where to take action.
- Performance Insights allows non-experts to detect performance problems with an easy-to-understand dashboard that visualizes database load.
- It displays the database load in an interactive graph, allowing you to analyze and troubleshoot the database workload.
- The load is categorized by SQL, waits, hosts, users, and other dimensions, providing detailed information about the sources of the load.
DocumentDB
- MongoDB is used to store, query, and index JSON data(Similar "deployment concepts" as Aurora)
- Fully Managed, highly available with replication across 3 AZ
- Automatically scales to workloads with millions of requests per seconds
- Storage scales automatically up to 64 TB without any impact to your application
- Supports millions of requests per second with up to 15 low latency read replicas
- Designed for 99.99% availability and replicates six copies of your data across three AZs
- Can migrate from MongoDB using the AWS Database Migration Service (AWS DMS)
Amazon Neptune
Fully managed graph database
- Highly available across 3 AZ, with up to 15 read replicas
- Build and run applications working with highly connected datasets – optimized for these complex and hard queries
- Can store up to billions of relations and query the graph with milliseconds latency
- Highly available with replications across multiple AZs
- Great for knowledge graphs (Wikipedia), fraud detection, recommendation engines, social networking
- Fully managed graph database service
- Build and run identity, knowledge, fraud graph, and other applications
- Deploy high performance graph applications using popular open-source APIs including:
- Gremlin
- openCypher
- SPARQL
- Offers greater than 99.99% availability
- Storage is fault-tolerant and self-healing
- DB volumes grow in increments of 10 GB up to a maximum of 64 TB
- Create up to 15 database read replicas
Example
A popular graph dataset would be a social network
- Users have friends
- Posts have comments
- Comments have likes from users
- Users share and like posts...
Amazon ElastiCache
ElastiCacheis to get managed Redis or Memcached- Caches are in-memory databases with high performance, low latency
- Helps reduce load off databases for read intensive workloads
- AWS takes care of OS maintenance / patching, optimizations, setup, configuration, monitoring, failure recovery and backups
- Using ElastiCache involves heavy application code changes
Note
ElastiCache nodes run on Amazon EC2 instances, so you must choose an instance family/type
Redis vs Memcached
- Multi AZ with Auto-Failover
- Read Replicas to scale reads and have high availability
- Data Durability using AOF persistence
- Backup and restore features
- Multi-node for partitioning of data (sharding)
- No high availability (replication)
- Non persistent
- No backup and restore
- Multi-threaded architecture
Cache Security
- All caches in ElastiCache:
- Do not support IAM authentication
- IAM policies on ElastiCache are only used for AWS API-level security
- Redis AUTH
- You can set a "password/token" when you create a Redis cluster
- This is an extra level of security for your cache (on top of security groups)
- Support SSL in flight encryption
- Memcached
- Supports SASL-based authentication (advanced)
Lazy Loading / Cache-Aside / Lazy Population
- Pros
- Only requested data is cached (the cache isn’t filled up with unused data)
- Node failures are not fatal (just increased latency to warm the cache)
- Cons
- Cache miss penalty that results in 3 round trips, noticeable delay for that request
- Stale data: data can be updated in the database and outdated in the cache
Write Through – Add or Update cache when database is updated
- Pros:
- Data in cache is never stale, reads are quick
- Write penalty vs Read penalty (each write requires 2 calls)
- Cons:
- Missing Data until it is added / updated in the DB
- Mitigation is to implement Lazy Loading strategy as well
- Cache churn – a lot of the data will never be read
Use Case
- Data that is relatively static and frequently accessed
- Applications that are tolerant of stale data
- Data is slow and expensive to get compared to cache retrieval
- Require push-button scalability for memory, writes and reads
- Often used for storing session state
Amazon Keyspaces(for Apache Cassandra)
Apache Cassandra is an open-source NoSQL distributed database
- A managed Apache Cassandra-compatible database service
- Serverless, Scalable, highly available, fully managed by AWS
- Automatically scale tables up/down based on the application’s traffic
- Tables are replicated 3 times across multiple AZ
- Single-digit millisecond latency at any scale, 1000s of requests per second
- Capacity: On-demand mode or provisioned mode with auto-scaling
- Encryption, backup, Point-In-Time Recovery (PITR) up to 35 days
- Use cases: store IoT devices info, time-series data, ...
Keyspacesenables you to use theCassandra Query Language (CQL)API code- Keyspaces is serverless and fully managed
- 99.99% availability SLA within an AWS Region
Amazon Managed Blockchain
- Blockchain makes it possible to build applications where multiple parties can execute transactions without the need for a trusted, central authority.
- Amazon Managed Blockchain is a managed service to:
- Join public blockchain networks
- Or create your own scalable private network
- Compatible with the frameworks Hyperledger Fabric & Ethereum
Amazon QLDB
QLDB stands for "Quantum Ledger Database"(A ledger is a book recording financial transactions)
- Fully Managed, Serverless, Highavailable, Replication across 3AZ
- Used to review history of all the changes made to your application data over time
- Immutable system: no entry can be removed or modified, cryptographically verifiable
- 2-3x better performance than common ledger blockchain frameworks, manipulate data using SQL
- Difference with Amazon Managed Blockchain: no decentralization component, in accordance with financial regulation rules
- Amazon QLDB has a built-in immutable journal that stores an accurate and sequenced entry of every data change
- The journal is append-only, meaning that data can only be added to a journal, and it cannot be overwritten or deleted
- Amazon QLDB uses cryptography to create a concise summary of your change history
- Generated using a cryptographic hash function (SHA-256)
- Serverless and offers automatic scalability
Amazon Timestream
- Fully managed, fast, scalable, serverless time series database
- Automatically scales up/down to adjust capacity
- Store and analyze trillions of events per day
- 1000s times faster & 1/10th the cost of relational databases
- Scheduled queries, multi-measure records, SQL compatibility
- Data storage tiering: recent data kept in memory and historical data kept in a cost-optimized storage
- Built-in time series analytics functions (helps you identify patterns in your data in near real-time)
- Encryption in transit and at rest
- Use cases: IoT apps, operational applications, real-time analytics, ...
Serverless
- With serverless there are no instances to manage
- You don’t need to provision hardware
- There is no management of operating systems or software
- Capacity provisioning and patching is handled automatically
- Provides automatic scaling and high availability
- Can be very cheap!
Example
- AWS Lambda
- DynamoDB
- AWS Cognito
- AWS API Gateway
- Amazon S3
- AWS SNS & SQS
- AWS Kinesis Data Firehose
- Aurora Serverless
- Step Functions
- Fargate
AWS Lambda
Benefits
- Easy Pricing:
- Pay per request and compute time
- Free tier of 1,000,000 AWS Lambda requests and 400,000 GBs of compute time
- Integrated with the whole AWS suite of services
- Event-Driven: functions get invoked by AWS when needed
- Integrated with many programming languages
- Easy monitoring through AWS CloudWatch
- Easy to get more resources per functions (up to 10GB of RAM!)
- Increasing RAM will also improve CPU and network!
Limits(per region)
- Execution:
- Memory allocation: 128 MB – 10GB (1 MB increments)
- Maximum execution time: 900 seconds (15 minutes)
- Environment variables (4 KB)
- Disk capacity in the "function container" (in /tmp): 512 MB to 10GB
- Concurrency executions:
- 3000 – US West (Oregon), US East (N. Virginia), Europe (Ireland)
- 1000 – Asia Pacific (Tokyo), Europe (Frankfurt), US East (Ohio)
- 500 – Other Regions
- If the concurrency limit is exceeded throttling occurs with error "Rate exceeded" and a 429 "TooManyRequestsException"
- Deployment:
- Lambda function deployment size (
compressed.zip): 50 MB - Size of uncompressed deployment (code + dependencies): 250 MB
- Can use the
/tmpdirectory to load other files at startup - Size of environment variables: 4 KB
- Lambda function deployment size (
Synchronous Invocations
- Results is returned right away
- Error handling must happen client side (retries, exponential backoff, etc…)
- User Invoked:
- Elastic Load Balancing (Application Load Balancer)
- Amazon API Gateway
- Amazon CloudFront (Lambda@Edge)
- Amazon S3 Batch
- Service Invoked:
- Amazon Cognito
- AWS Step Functions
- Other Services:
- Amazon Lex
- Amazon Alexa
- Amazon Kinesis Data Firehose
Asynchronous Invocations
- The events are placed in an
Event Queue - Lambda attempts to retry on errors
- 3 tries total
- 1 minute wait after 1st, then 2 minutes wait
- Make sure the processing is idempotent (in case of retries)
- If the function is retried, you will see duplicate logs entries in CloudWatch Logs
- Can define a DLQ (dead-letter queue) – SNS or SQS – for failed processing (need correct IAM permissions)
- Asynchronous invocations allow you to speed up the processing if you don’t need to wait for the result (ex: you need 1000 files processed)
Lambda Integration with ALB
- To expose a Lambda function as an HTTP(S) endpoint, You can use the Application Load Balancer (or an API Gateway)
-
The Lambda function must be registered in a target group
-
ALB can support multi-header values (ALB setting)
- When you enable multi-value headers, HTTP headers and query string parameters that are sent with multiple values are shown as arrays within the AWS Lambda event and response objects.
Lambda in VPC
By default, your Lambda function is launched outside your own VPC (in an AWS-owned VPC)
Therefore it cannot access resources in your VPC (RDS, ElastiCache, internal ELB…)
- You must define the VPC ID, the Subnets and the Security Groups
- Lambda will create an ENI (Elastic Network Interface) in your subnets
- AWSLambdaVPCAccessExecutionRole
- A Lambda function in your VPC does not have internet access
- Deploying a Lambda function in a public subnet does not give it internet access or a public IP
- Deploying a Lambda function in a private subnet gives it internet access if you have a NAT Gateway / Instance
- You can use VPC endpoints to privately access AWS services without a NAT
Lambda Function Configuration
- RAM:
- From 128MB to 10GB in 1MB increments
- The more RAM you add, the more vCPU credits you get
- At 1,792 MB, a function has the equivalent of one full vCPU
- After 1,792 MB, you get more than one CPU, and need to use multi-threading in your code to benefit from it (up to 6 vCPU)
- If your application is CPU-bound (computation heavy), increase RAM
- Timeout: default 3 seconds, maximum is 900 seconds (15 minutes)
Amazon Aurora
- Aurora is a proprietary technology(not open sourced) from AWS
- PostgreSQL and MySQL are both supported as Aurora DB (that means your drivers will work as if Aurora was a Postgres or MySQL database)
- Aurora is "AWS cloud optimized" and claims 5x performance improvement over MySQL on RDS, over 3x the performance of Postgres on RDS
- Aurora storage automatically grows in increments of 10GB, up to 128 TB
- Aurora can have 15 replicas while MySQL has 5, and the replication process is faster (sub 10 ms replica lag)
- Failover in Aurora is instantaneous. It’s HA (High Availability) native.
- Aurora costs more than RDS (20% more) – but is more efficient
- Not in the free tier
Aurora High Availability and Read Scaling
- 6 copies of your data across 3 AZ:
- 4 copies out of 6 needed for writes
- 3 copies out of 6 need for reads
- Self healing with peer-to-peer replication
- Storage is striped across 100s of volumes
- One Aurora Instance takes writes (master)
- Automated failover for master in less than 30 seconds
- Master + up to 15 Aurora Read Replicas serve reads
- Support for Cross Region Replication
Features
- Automatic failover
- Backup and Recovery
- Isolation and security
- Industry compliance
- Push-button scaling
- Automated Patching with Zero Downtime
- Advanced Monitoring
- Routine Maintenance
- Backtrack: restore data at any point of time without using backups
Aurora Fault Tolerance and Aurora Replicas
- Fault tolerance across 3 AZs
- Single logical volume
- Aurora Replicas scale-out read requests
- Up to 15 Aurora Replicas with
sub-10msreplica lag - Aurora Replicas are independent endpoints
- Can
promoteAurora Replica to be a new primary or create new primary - Set priority (tiers) on Aurora Replicas to control order of promotion
- Can use
Auto Scalingto add replicas
Custom Endpoints
- Define a subset of Aurora Instances as a Custom Endpoint
- Example: Run analytical queries on specific replicas
- The Reader Endpoint is generally not used after defining Custom Endpoints
Aurora Serverless
- Automated database instantiation and auto- scaling based on actual usage
- Good for infrequent, intermittent or unpredictable workloads
- No capacity planning needed
- Pay per second, can be more cost-effective
Global Aurora
- Aurora Cross Region Read Replicas:
- Useful for disaster recovery
- Simple to put in place
- Aurora Global Database (recommended):
- 1 Primary Region (read / write)
- Up to 5 secondary (read-only) regions, replication lag is less than 1 second
- Up to 16 Read Replicas per secondary region
- Helps for decreasing latency
- Promoting another region (for disaster recovery) has an RTO of < 1 minute
- Typical cross-region replication takes less than 1 second
Aurora Multi-Master
Multi-master clusters are best suited for segmented workloads, such as for multitenant applications.
- All nodes allow reads/writes
- Available for MySQL only
- Up to four read/write nodes
- Single Region only
- Cannot have cross-Region replicas
- Can work with active-active and active-passive workloads
- Can restart read/write DB instance without impacting other instances
Aurora Serverless
- Capacity seamlessly scales up and down
- Each Aurora Capacity Unit (ACU) is 2 GB of memory plus CPU
- Use Cases
- Infrequently used applications
- New applications
- Variable workloads
- Unpredictable workloads
- Development and test databases
- Multi-tenant applications
Aurora Machine Learning
- Enables you to add ML-based predictions to your applications via SQL
- Simple, optimized, and secure integration between Aurora and AWS ML services
- Supported services
- Amazon SageMaker (use with any ML model)
- Amazon Comprehend (for sentiment analysis)
- You don’t need to have ML experience
- Use cases: fraud detection, ads targeting, sentiment analysis, product recommendations
Aurora Database Cloning
- Create a new Aurora DB Cluster from an existing one
- Faster than snapshot & restore
- The new DB cluster uses the same cluster volume and data as the original but will change when data updates are made
- Very fast & cost-effective
- Useful to create a "staging" database from a "production" database without impacting the production database
RDS & Aurora Security
- At-rest encryption:
- Database master & replicas encryption using AWS KMS – must be defined as launch time
- If the master is not encrypted, the read replicas cannot be encrypted
- To encrypt an un-encrypted database, go through a DB snapshot & restore as encrypted
- In-flight encryption: TLS-ready by default,use the AWS TLS root certificates client-side
- IAM Authentication: IAM roles to connect to your database (instead of username/pw)
- Security Groups: Control Network access to your RDS / Aurora DB
- No SSH available except on RDS Custom
- Audit Logs can be enabled and sent to CloudWatch Logs for longer retention
Aurora Backups
- Aurora backups are continuous and incremental so you can quickly restore to any point within the backup retention period
- For Amazon Aurora DB clusters, the default backup retention period is one day regardless of how the DB cluster is created
- You can't disable automated backups on Aurora. The backup retention period for Aurora is managed by the DB cluster
- You can also use AWS Backup to manage backups of Amazon Aurora DB clusters
- You can also take DB cluster snapshots which capture a snapshot of the entire DB cluster
- Manual snapshots aren't subject to the backup retention period and do not expire
- For very long-term backups, you can export snapshot data to Amazon S3
- With Amazon Aurora, you can copy automated backups or manual DB cluster snapshots
- You can copy a snapshot within the same AWS Region, you can copy a snapshot across AWS Regions, and you can copy shared snapshots
- Amazon RDS deletes automated backups in several situations:
- At the end of their retention period
- When you disable automated backups for a DB cluster
- When you delete a DB cluster
- If you want to keep an automated backup for a longer period, copy it to create a manual snapshot
DynamoDB
- Fully Managed Highly available with replication across 3 AZ
- NoSQL database(key/value) with transaction support
- Scales to massive workloads, distributed "serverless" database
- Millions of requests per seconds, trillions of row, 100s of TB of storage
- Fast and consistent in performance
- Single-digit millisecond latency – low latency retrieval
- Integrated with IAM for security, authorization and administration
- Enables event driven programming with DynamoDB Streams
- Low cost and auto scaling capabilities
- Standard & Infrequent Access (IA) Table Class
Basics
- DynamoDB is made of Tables
- Each table has a Primary Key (must be decided at creation time)
- Each table can have an infinite number of items (= rows)
- Each item has attributes (can be added over time – can be null)
- Maximum size of an item is 400KB
- Data types supported are:
- Scalar Types – String, Number, Binary, Boolean, Null
- Document Types – List, Map
- Set Types – String Set, Number Set, Binary Set
Primary Keys
- Option 1: Partition Key (HASH)
- Partition key must be unique for each item
- Partition key must be "diverse" so that the data is distributed
- Option 2: Partition Key + Sort Key (HASH + RANGE)
- The combination must be unique for each item
- Data is grouped by partition key
Read/Write Capacity Modes
Control how you manage your table’s capacity (read/write throughput)
- Provisioned Mode (default)
- You specify the number of reads/writes per second
- You need to plan capacity beforehand
- Pay for provisioned Read Capacity Units (RCU) & Write Capacity Units (WCU)
- Possibility to add auto-scaling mode for RCU & WCU
- On-Demand Mode
- Read/writes automatically scale up/down with your workloads
- No capacity planning needed
- Pay for what you use, more expensive ($$$)
- Great for unpredictable workloads, steep sudden spikes
Note
- One Write Capacity Unit (WCU) represents one write per second for an item up to 1 KB in size
- If the items are larger than 1 KB, more WCUs are consumed
- One Read Capacity Unit (RCU) represents one Strongly Consistent Read per second, or two Eventually Consistent Reads per second, for an item up to 4 KB in size
- If the items are larger than 4 KB, more RCUs are consumed
DynamoDB Time to Live (TTL)
- TTL lets you define when items in a table expire so that they can be automatically deleted from the database
- With TTL enabled on a table, you can set a timestamp for deletion on a per-item basis
- No extra cost and does not use WCU / RCU
- Helps reduce storage and manage the table size over time
Throttling
- If we exceed provisioned RCUs or WCUs, we get "ProvisionedThroughputExceededException"
- Reasons:
- Hot Keys – one partition key is being read too many times
- Hot Partitions
- Very large items(RCU and WCU depends on size of items)
- Solutions:
- Exponential backoff when exception is encountered (already in SDK)
- Distribute partition keys as much as possible
- If RCU issue, we can use DynamoDB Accelerator (DAX)
DynamoDB Accelerator - DAX
- Fully Managed in-memory cache for DynamoDB
- 10x performance improvement – single- digit millisecond latency to microseconds latency – when accessing your DynamoDB tables
- Secure, highly scalable & highly available
- Can be a read-through cache and a write-through cache
- Used to improve READ and WRITE performance
- You do not need to modify application logic, since DAX is compatible with existing DynamoDB API calls
- Difference with ElastiCache at the CCP level:
- DAX is only used for and is integrated with DynamoDB
- ElastiCache can be used for other databases
DynamoDB Streams
- Captures a time-ordered sequence of item-level modifications in any DynamoDB table and stores this information in a log for up to 24 hours
- Can configure the information that is written to the stream:
KEYS_ONLY— Only the key attributes of the modified itemNEW_IMAGE— The entire item, as it appears after it was modifiedOLD_IMAGE— The entire item, as it appeared before it was modifiedNEW_AND_OLD_IMAGES— Both the new and the old images of the item
Global Tables
- Make a DynamoDB table accessible with low latency in multiple-regions
- Active-Active replication (read/write to any AWS Region)
- Applications can READ and WRITE to the table in any region
- Must enable DynamoDB Streams as a pre-requisite
Integration with Amazon S3
- Works for any point of time in the last 35 days
- Doesn’t affect the read capacity of your table
- Perform data analysis on top of DynamoDB
- Retain snapshots for auditing
- ETL on top of S3 data before importing back into DynamoDB
- Export in DynamoDB JSON or ION format
- Import CSV,DynamoDB JSON or ION format
- Doesn’t consume any write capacity
- Creates a new table
- Import errors are logged in CloudWatch Logs
Local Secondary Index (LSI)
- Alternative Sort Key for your table (same Partition Key as that of base table)
- The Sort Key consists of one scalar attribute (String, Number, or Binary)
- Up to 5 Local Secondary Indexes per table
- Must be defined at table creation time
- Attribute Projections – can contain some or all the attributes of the base table (KEYS_ONLY, INCLUDE, ALL)
Global Secondary Index (GSI)
- Alternative Primary Key (HASH or HASH+RANGE) from the base table
- Speed up queries on non-key attributes
- The Index Key consists of scalar attributes (String, Number, or Binary)
- Attribute Projections – some or all the attributes of the base table (KEYS_ONLY, INCLUDE, ALL)
- Must provision RCUs & WCUs for the index
- Can be added/modified after table creation
Indexes and Throttling
- Global Secondary Index (GSI):
- If the writes are throttled on the GSI, then the main table will be throttled!
- Even if the WCU on the main tables are fine
- Choose your GSI partition key carefully!
- Assign your WCU capacity carefully!
- Local Secondary Index (LSI):
- Uses the WCUs and RCUs of the main table
- No special throttling considerations
CloudFront Functions
- Lightweight functions written in JavaScript
- For high-scale, latency-sensitive CDN customizations
- Sub-ms startup times, millions of requests/second
- Used to change Viewer requests and responses:
- Viewer Request: after CloudFront receives a request from a viewer
- Viewer Response: before CloudFront forwards the response to the viewer
- Native feature of CloudFront (manage code entirely within CloudFront)
Amazon API Gateway
- Fully managed service for developers to easily create, publish, maintain, monitor, and secure APIs
- Serverless and scalable
- Supports RESTful APIs and WebSocket APIs
- Support for security, user authentication, API throttling, API keys, monitoring...
- Handle API versioning (v1, v2...)
- Handle different environments (dev, test, prod...)
- Handle security (Authentication and Authorization)
- Create API keys, handle request throttling
- Swagger / Open API import to quickly define APIs
- Transform and validate requests and responses
- Generate SDK and API specifications
- Cache API responses
Endpoint Types
- Edge-Optimized (default): For global clients
- Requests are routed through the CloudFront Edge locations (improves latency)
- The API Gateway still lives in only one region
- Regional:
- For clients within the same region
- Could manually combine with CloudFront (more control over the caching strategies and the distribution)
- Private:
- Can only be accessed from your VPC using an interface VPC endpoint (ENI)
- Use a resource policy to define access
Caching
- You can add caching to API calls by provisioning an Amazon API Gateway cache and specifying its size in gigabytes
- Caching allows you to cache the endpoint's response
- Caching can reduce number of calls to the backend and improve latency of requests to the API
Security
- User Authentication through
- IAM Roles (useful for internal applications)
- Cognito (identity for external users – example mobile users)
- Custom Authorizer (your own logic)
- Custom Domain Name HTTPS security through integration with AWS Certificate Manager (ACM)
- If using Edge-Optimized endpoint, then the certificate must be in us-east-1
- If using Regional endpoint, the certificate must be in the API Gateway region
- Must setup CNAME or A-alias record in Route 53
Deployment Stages
- Making changes in the API Gateway does not mean they’re effective
- You need to make a "deployment" for them to be in effect
- It’s a common source of confusion
- Changes are deployed to "Stages" (as many as you want)
- Use the naming you like for stages (dev, test, prod)
- Each stage has its own configuration parameters
- Stages can be rolled back as a history of deployments is kept
Stage Variables
- Stage variables are like environment variables for API Gateway
- Use them to change often changing configuration values
- They can be used in:
- Lambda function ARN
- HTTP Endpoint
- Parameter mapping templates
- Use cases:
- Configure HTTP endpoints your stages talk to (dev, test, prod…)
- Pass configuration parameters to AWS Lambda through mapping templates
- Stage variables are passed to the "context" object in AWS Lambda
Integration Types
- Integration Type MOCK
- API Gateway returns a response without sending the request to the backend
- Integration Type HTTP / AWS (Lambda & AWS Services)
- you must configure both the integration request and integration response
- Setup data mapping using mapping templates for the request & response
- Integration Type AWS_PROXY (Lambda Proxy):
- incoming request from the client is the input to Lambda
- The function is responsible for the logic of request / response
- No mapping template, headers, query string parameters… are passed as arguments
- Integration Type HTTP_PROXY
- No mapping template
- The HTTP request is passed to the backend
- The HTTP response from the backend is forwarded by API Gateway
Mapping Templates (AWS & HTTP Integration)
- Mapping templates can be used to modify request / responses
- Rename / Modify query string parameters
- Modify body content
- Add headers
- Uses Velocity Template Language (VTL): for loop, if etc…
- Filter output results (remove unnecessary data)
Throttling
- API Gateway sets a limit on a steady-state rate and a burst of request submissions against all APIs in your account
- Limits:
- By default API Gateway limits the steady-state request rate to 10,000 requests per second
- The maximum concurrent requests is 5,000 requests across all APIs within an AWS account
- If you go over 10,000 requests per second or 5,000 concurrent requests you will receive a
429 Too Many Requestserror response
- Upon catching such exceptions, the client can resubmit the failed requests in a way that is rate limiting, while complying with the API Gateway throttling limits
Usage Plan & API Keys
- Usage Plan:
- who can access one or more deployed API stages and methods
- how much and how fast they can access them
- uses API keys to identify API clients and meter access
- configure throttling limits and quota limits that are enforced on individual client
- API Keys:
- alphanumeric string values to distribute to your customers
- Ex: WBjHxNtoAb4WPKBC7cGm64CBibIb24b4jt8jJHo9
- Can use with usage plans to control access
- Throttling limits are applied to the API keys
- Quotas limits is the overall number of maximum requests
Amazon Cognito
AWS Service that offers Authentication and Authorization features
- Give users an identity to interact with our web or mobile application
- Allows you to add user registration, sign in, and access control
- Scalable and Highly available supporting millions of users
- Supports standards based Identity Providers(OAuth 2.0, OIDC, SAML)
- Useful in a variety of contexts:
- Keeping an active directory of Users
- Security APIs
- Providing temporary access to AWS resources
Cognito User Pools
Create a serverless database of user for your web & mobile apps
User pools help you track user device, location, and IP address, and adapt to sign-in requests of different risk levels
- Features:
- Simple login: Username (or email) / password combination
- Password reset
- Email & Phone Number Verification
- Multi-factor authentication (MFA)
- Federated Identities: users from Facebook, Google, SAML…
- Feature: block users if their credentials are compromised elsewhere
- Login sends back a JSON Web Token (JWT)
- Hosted Authentication UI
- Cognito has a hosted authentication UI that you can add to your app to handle sign up and sign-in workflows
- Using the hosted UI, you have a foundation for integration with social logins, OIDC or SAML
- Can customize with a custom logo, custom CSS, and the URL(not the underlying JavaScript)
Tip
Groups can be created with Amazon Cognito user pools to manage permissions to different types of users.
While accessing the application, users get authenticated by Amazon Cognito user pool.
Users in separate groups in Cognito will be mapped to separate IAM roles & receive tokens.
These tokens are validated by API Gateway for granting access to application or to backend Lambda function.
Cognito Identity Pools (Federated Identity)
- Get identities for "users" so they obtain temporary AWS credentials
- Your identity pool (e.g identity source) can include:
- Public Providers (Login with Amazon, Facebook, Google, Apple)
- Users in an Amazon Cognito user pool
- OpenID Connect Providers & SAML Identity Providers
- Developer Authenticated Identities (custom login server)
- Cognito Identity Pools allow for unauthenticated (guest) access
- Users can then access AWS services directly or through API Gateway
- The IAM policies applied to the credentials are defined in Cognito
- They can be customized based on the user_id for fine grained control
AWS Step Functions
AWS Step Functions is used to build distributed applications as a series of steps in a visual workflow
- You can quickly build and run state machines to execute the steps of your application
- Features: sequence, parallel, conditions, timeouts, error handling, ...
- How it works:
- Define the steps of your workflow in the
JSON-based Amazon States Language. The visual console automatically graphs each step in the order of execution - Start an execution to visualize and verify the steps of your application are operating as intended. The console highlights the real-time status of each step and provides a detailed history of every execution
- AWS Step Functions operates and scales the steps of your application and underlying compute for you to help ensure your application executes reliably under increasing demand
- Define the steps of your workflow in the
- Can integrate with EC2, ECS, On-premises servers, API Gateway, SQS queues, etc...
- Possibility of implementing human approval feature
- Use cases: order fulfillment, data processing, web applications, any workflow
Task States
- Do some work in your state machine
- Invoke one AWS service
- Can invoke a Lambda function
- Run an AWS Batch job
- Run an ECS task and wait for it to complete
- Insert an item from DynamoDB
- Publish message to SNS, SQS
- Launch another Step Function workflow…
- Run an one Activity
- EC2, Amazon ECS, on-premises
- Activities poll the Step functions for work
- Activities send results back to Step Functions
States
- Choice State -Test for a condition to send to a branch (or default branch)
- Fail or Succeed State - Stop execution with failure or success
- Pass State - Simply pass its input to its output or inject some fixed data, without performing work.
- Wait State - Provide a delay for a certain amount of time or until a specified time/date.
- Map State - Dynamically iterate steps.
- Parallel State - Begin parallel branches of execution.
Error Handling in Step Functions
- Any state can encounter runtime errors for various reasons:
- State machine definition issues (for example, no matching rule in a Choice state)
- Task failures (for example, an exception in a Lambda function)
- Transient issues (for example, network partition events)
- Use Retry (to retry failed state) and Catch (transition to failure path) in the State Machine to handle the errors instead of inside the Application Code
- Predefined error codes:
- States.ALL : matches any error name
- States.Timeout: Task ran longer than TimeoutSeconds or no heartbeat received
- States.TaskFailed: execution failure
- States.Permissions: insufficient privileges to execute code
- The state may report is own errors
AWS Amplify
- Set of tools to get started with creating mobile and full-stack web applications
- "Elastic Beanstalk for mobile and web applications"
- Build web and mobile backends, and web frontend UIs
- Must-have features such as data storage, authentication, storage, and machine-learning, all powered by AWS services
- Front-end libraries with ready-to-use components for React.js, Vue, React Native, iOS, Android, Flutter, etc…
- Incorporates AWS best practices to for reliability, security, scalability
- Build and deploy with the
Amplify CLIorAmplify Studio - AWS Amplify Hosting is a fully managed CI/CD and hosting service for fast, secure, and reliable static and server-side rendered apps
Components
Amplify Studio- Visually build a full-stack app, both front-end UI and a backend
- Use the visual interface to define a data model, user authentication, and file storage without backend expertise
- Easily add AWS services not available within Amplify Studio using the
AWS Cloud Development Kit (CDK)
Amplify CLI- Configure an Amplify backend With a guided CLI workflowAmplify Libraries- Connect your app to existing AWS Services (Cognito, S3 and more)Amplify Hosting- Host secure, reliable, fast web apps or websites via the AWS content delivery network
AWS AppSync
- AWS AppSync is a fully managed service that makes it easy to develop GraphQL APIs
- Applications can securely access, manipulate, and receive real-time updates from multiple data sources such as databases or APIs
- AWS AppSync automatically scales a GraphQL API execution engine up and down to meet API request volumes
- Uses GraphQL, a data language that enables client apps to fetch, change and subscribe to data from servers
- AWS AppSync lets you specify which portions of your data should be available in a real-time manner using GraphQL Subscriptions
- AWS AppSync supports
AWS Lambda,Amazon DynamoDB, andAmazon Elasticsearch - Server-side data caching capabilities reduce the need to directly access data sources
- AppSync is fully managed and eliminates the operational overhead of managing cache clusters
AWS Batch
- Fully managed batch processing at any scale
- Efficiently run 100,000s of computing batch jobs on AWS
- A "batch" job is a job with a start and an end (opposed to continuous)
- Batch will dynamically launch EC2 instances or Spot Instances
- AWS Batch provisions the right amount of compute / memory
- You submit or schedule batch jobs and AWS Batch does the rest!
- Batch jobs are defined as Docker images and run on ECS
- Helpful for cost optimizations and focusing less on the infrastructure
Batch VS Lambda
- Time limit
- Limited runtimes
- Limited temporary disk space
- Serverless
- No time limit
- Any runtime as long as it’s packaged as a Docker image
- Rely on EBS / instance store for disk space
- Relies on EC2 (can be managed by AWS)
Amazon Lightsail
- Virtual servers, storage, databases, and networking
- Low & predictable pricing
- Simpler alternative to using EC2, RDS, ELB, EBS, Route 53...
- Great for people with little cloud experience!
- Can setup notifications and monitoring of your Lightsail resources
- Use cases:
- Simple web applications (has templates for LAMP, Nginx, MEAN, Node.js...)
- Websites (templates for WordPress, Magento, Plesk, Joomla)
- Dev /Test environment
- Has high availability but no auto-scaling, limited AWS integrations
Data & Analytics
Amazon Athena
- Serverless query service to analyze data stored in Amazon
S3 - Uses standard SQL language to query the files
- Supports CSV, TSV, JSON, ORC, Avro, and Parquet(builtonPresto)
- Pricing: $5.00 per TB of data scanned
- Commonly used with Amazon Quicksight for repor ting/dashboards
- Use compressed or columnar data for cost-savings (less scan)
- Use cases: Business intelligence / analytics / reporting, analyze & query VPC Flow Logs, ELB Logs, CloudTrail trails, etc...
Federated Query
- Allows you to run SQL queries across data stored in relational, non-relational, object, and custom data sources (AWS or on-premises)
- Uses Data Source Connectors that run on AWS Lambda to run Federated Queries (e.g., CloudWatch Logs, DynamoDB, RDS, ...)
- Store the results back in Amazon S3
Optimizing Athena for Performance
- Partition your data
- Bucket your data – bucket the data within a single partition
- Use Compression – AWS recommend using either Apache Parquet or Apache ORC
- Optimize file sizes
- Optimize columnar data store generation – Apache Parquet and Apache ORC are popular columnar data stores
- Optimize ORDER BY and Optimize GROUP BY
- Use approximate functions
- Only include the columns that you need
Redshift
- Redshift is based on PostgreSQL, but it’s not used for OLTP
- It’s OLAP – online analytical processing (analytics and data warehousing)
- Load data once every hour, not every second
- 10x better performance than other data warehouses, scale to PBs of data
- Columnar storage of data (instead of row based)
- Massively Parallel Query Execution (MPP), highly available
- Pay as you go based on the instances provisioned
- Has a SQL interface for performing the queries
- BI tools such as AWS Quicksight or Tableau integrate with it
- vs Athena: faster queries / joins / aggregations thanks to indexes
Cluster
- Leader node: for query planning, results aggregation
- Compute node: for performing the queries, send results to leader
- You provision the node size in advance
- You can used Reserved Instances for cost savings
Snapshots & DR
- Redshift has no "Multi-AZ" mode
- Snapshots are point-in-time backups of a cluster, stored internally in S3
- Snapshots are incremental (only what has changed is saved)
- You can restore a snapshot into a new cluster
- Automated: every 8 hours, every 5 GB, or on a schedule. Set retention between 1 to 35 days
- Manual: snapshot is retained until you delete it
- You can configure Amazon Redshift to automatically copy snapshots (automated or manual) of a cluster to another AWS Region
Spectrum
- Query data that is already in S3 without loading it
- Must have a Redshift cluster available to start the query
- The query is then submitted to thousands of Redshift Spectrum nodes
RedShift Use Cases
- Perform complex queries on massive collections of structured and semi-structured data and get fast performance
- Frequently accessed data that needs a consistent, highly structured format
- Use Spectrum for direct access of S3 objects in a data lake
- Managed data warehouse solution with:
- Automated provisioning, configuration and patching
- Data durability with continuous backup to S3
- Scales with simple API calls
- Exabyte scale query capability
OpenSearch Service
Amazon OpenSearch is successor to
Amazon ElasticSearch
- In DynamoDB, queries only exist by primary key or indexes... -> With OpenSearch, you can search any field, even partially matches
- It’s common to use OpenSearch as a complement to another database
- Search, visualize, and analyze text and unstructured data
- Deploy nodes and replicas across AZs
- OpenSearch requires a cluster of instances (not serverless)
- Does not support SQL (it has its own query language)
- Ingestion from Kinesis Data Firehose, AWS IoT, and CloudWatch Logs
- Security through Cognito & IAM, KMS encryption,TLS
- Comes with OpenSearch Dashboards (visualization)
Service Deployment
- Clusters are created (Management Console, API, or CLI)
- Clusters are also known as OpenSearch Service domains
- You specify the number of instances and instance types
- Storage options include UltraWarm or Cold storage
OpenSearch in an Amazon VPC
- Clusters can be deployed in a VPC for secure intra-VPC communications
- VPN or proxy required to connect from the internet (public domains are directly accessible)
- Cannot use IP-based access policies
- Limitations of VPC deployments:
- You can’t switch from VPC to a public endpoint. The reverse is also true
- You can’t launch your domain within a VPC that uses dedicated tenancy
- After you place a domain within a VPC, you can’t move it to a different VPC, but you can change the subnets and security group settings
The ELK Stack
- ELK stands for
Elasticsearch,Logstash, andKibana - This is a popular combination of projects
- Aggregate logs from systems and applications, analyze these logs, and create visualizations
- Use cases include:
- Visualizing application and infrastructure monitoring data
- Troubleshooting
- Security analytics
Access Control
Resource-based policies– often called a domain access policyIdentity-based policies– attached to users or roles (principals)IP-based policies– Restrict access to one or more IP addresses or CIDR blocksFine-grained access control– Provides:- Role-based access control
- Security at the index, document, and field level
- OpenSearch Dashboards multi-tenancy
- HTTP basic authentication for OpenSearch and OpenSearch Dashboards
Tip
Authentication options include:
- Federation using SAML to on-premises directories
- Amazon Cognito and social identity providers
Best Practices
- Deploy OpenSearch data instances across three Availability Zones (AZs) for the best availability
- Provision instances in multiples of three for equal distribution across AZs
- If three AZs are not available use two AZs with equal numbers of instances
- Use three dedicated master nodes
- Configure at least one replica for each index
- Apply restrictive resource-based access policies to the domain (or use fine-grained access control)
- Create the domain within an Amazon VPC
- For sensitive data enable node-to-node encryption and encryption at rest
Amazon EMR
EMR stands for "Elastic MapReduce"
- EMR helps creating Hadoop clusters (Big Data) to analyze and process vast amount of data
- The clusters can be made of hundreds of EC2 instances
- Also supports Apache Spark, HBase, Presto, Flink...
- EMR takes care of all the provisioning and configuration
- Auto-scaling and integrated with Spot instances
- Use cases: data processing, machine learning, web indexing, big data...
Node types & purchasing
- Master Node: Manage the cluster, coordinate, manage health – long running
- Core Node: Run tasks and store data – long running
- Task Node (optional): Just to run tasks – usually Spot
- Purchasing options:
- On-demand: reliable, predictable, won’t be terminated
- Reserved (min 1 year): cost savings (EMR will automatically use if available)
- Spot Instances: cheaper, can be terminated, less reliable
- Can have long-running cluster, or transient (temporary) cluster
Amazon QuickSight
- Serverless machine learning-powered business intelligence service to create interactive dashboards
- Fast, automatically scalable, embeddable, with per-session pricing
- Use cases:
- Business analytics
- Building visualizations
- Perform ad-hoc analysis
- Get business insights using data
- Integrated with RDS, Aurora, Athena, Redshift, S3...
- In-memory computation using SPICE engine if data is imported into QuickSight
- Enterprise edition: Possibility to setup Column-Level security (CLS)
AWS Glue
- Managed extract, transform, and load (ETL) service
- Useful to prepare and transform data for analytics
- AWS Glue runs the ETL jobs on a fully managed, scale-out
Apache Sparkenvironment - AWS Glue discovers data and stores the associated metadata(e.g. table definition and schema) in the AWS Glue Data Catalog
- Works with data lakes (e.g. data on S3), data warehouses (including RedShift), and data stores (including RDS or EC2 databases)
- Fully serverless service
Glue Job Bookmarks: prevent re-processing old dataGlue Elastic Views:- Combine and replicate data across multiple data stores using SQL
- No custom code, Glue monitors for changes in the source data, serverless
- Leverages a "virtual table" (materialized view)
Glue DataBrew: clean and normalize data using pre-built transformationGlue Studio: new GUI to create, run and monitor ETL jobs in GlueGlue Streaming ETL(built on Apache Spark Structured Streaming): compatible with Kinesis Data Streaming, Kafka, MSK (managed Kafka)
Tip
- You can use a crawler to populate the AWS Glue Data Catalog with tables
- A crawler can crawl multiple data stores in a single run
- Upon completion, the crawler creates or updates one or more tables in your Data Catalog
AWS Lake Formation
- Data lake = central place to have all your data for analytics purposes
- Fully managed service that makes it easy to setup a data lake in days
- Discover, cleanse, transform, and ingest data into your Data Lake
- It automates many complex manual steps (collecting, cleansing, moving, cataloging data, ...) and de-duplicate (using ML Transforms)
- Combine structured and unstructured data in the data lake
- Out-of-the-box source blueprints: S3, RDS, Relational & NoSQL DB...
- Fine-grained Access Control for your applications (row and column-level)
- Built on top of AWS Glue
AWS Data Exchange
- AWS Data Exchange is a data marketplace with over 3,000 products from 250+ providers
- AWS Data Exchange supports Data Files, Data Tables, and Data APIs
- Consume directly into data lakes, applications, analytics, and machine learning models
- Automatically export new or updated data sets to Amazon S3
- Query data tables with AWS Data Exchange for Amazon Redshift
- Use AWS-native authentication and governance, AWS SDKs, and consistent API documentation
AWS Data Pipeline
- AWS Data Pipeline is a managed ETL (Extract-Transform-Load) service
- Process and move data between different AWS compute and storage services
- Data sources can also be on-premises
- Data can be processed and transformed
- Results can be loaded to services such as Amazon S3, Amazon RDS, Amazon DynamoDB, and Amazon EMR
Amazon Managed Streaming for Apache Kafka (MSK)
- Amazon MSK is used for ingesting and processing streaming data in real-time
- Build and run Apache Kafka applications
- It is a fully managed service
- Provisions, configures, and maintains Apache Kafka clusters and Apache ZooKeeper nodes
- Security levels include:
- VPC network isolation
- AWS IAM for control-plane API authorization
- Encryption at rest
- TLS encryption in-transit
- TLS based certificate authentication
- SASL/SCRAM authentication secured by AWS Secrets Manager
Deploying and Managing
AWS CLI
--dry-run: not actually run the commandssts decode-authorization-message: decode long error messagehttp://169.254.169.254/latest/meta-data: EC2 Instance Metadataaws sts get-session-token: create a temporary session to use MFA with CLI
AWS CLI Credentials Provider Chain
The CLI will look for credentials in this order:
- Command line options –
--region,--output, and--profile - Environment variables –
AWS_ACCESS_KEY_ID,AWS_SECRET_ACCESS_KEY, andAWS_SESSION_TOKEN - CLI credentials file –
aws configure ~/.aws/credentialson Linux / Mac &C:\Users\USERNAME\.aws\credentialson Windows - CLI configuration file –
aws configure ~/.aws/configon Linux / macOS &C:\Users\USERNAME\.aws\configon Windows - Container credentials – for ECS tasks
- Instance profile credentials – for EC2 Instance Profiles
AWS Cloud Development Kit (CDK)
- Define your cloud infrastructure using a familiar language:
- JavaScript/TypeScript
- Python
- Java
- .NET
- The code is "compiled" into a CloudFormation template (JSON/YAML)
- You can therefore deploy infrastructure and application runtime code together
- Great for Lambda functions
- Great for Docker containers in ECS / EKS
CloudFormation
CloudFormation is a declarative way of outlining your AWS Infrastructure
Benefits
- Infrastructure as code
- No resources are manually created, which is excellent for control
- The code can be version controlled
- Changes to the infrastructure are reviewed through code
- Cost
- Each resources within the stack is tagged with an identifier so you can easily see how much a stack costs you
- You can estimate the costs of your resources using the CloudFormation template
- Savings strategy: In Dev, you could automation deletion of templates at 6 PM and recreated at 9 AM, safely
- Productivity
- Ability to destroy and re-create an infrastructure on the cloud on the fly
- Automated generation of Diagram for your templates!
- Declarative programming (no need to figure out ordering and orchestration)
- Separation of concern: create many stacks for many apps, and many layers
- Don’t re-invent the wheel
- Leverage existing templates on the web!
- Leverage the documentation
- Supports (almost) all AWS resources:
- You can use "custom resources" for resources that are not supported
Components
- Template - The JSON or YAML text file that contains the instructions for building out the AWS environment
- Stacks - The entire environment described by the template and created, updated, and deleted as a single unit
- StackSets - AWS CloudFormation StackSets extends the functionality of stacks by enabling you to create, update, or delete stacks across multiple accounts and regions with a single operation
- Change Sets - A summary of proposed changes to your stack that will allow you to see how those changes might impact your existing resources before implementing them
Templates
- A template is a YAML or JSON template used to describe the end-state of the infrastructure you are provisioning or changing
- After creating the template, you upload it to CloudFormation directly or using Amazon S3
- CloudFormation reads the template and makes the API calls on your behalf
- The resulting resources are called a "Stack"
Logical IDs– used to reference resources within the templatePhysical IDs– identify resources outside of AWS CloudFormation templates, but only after the resources have been created
- The required Resources section declares the AWS resources that you want to include in the stack, such as an Amazon EC2 instance or an Amazon S3 bucket
- This is a mandatory section
- Resources are declared and can reference each other
- Use the optional Parameters section to customize your templates
- Parameters enable you to input custom values to your template each time you create or update a stack
- Useful for template reuse
The optional Mappings section matches a key to a corresponding set of named values
Tip
With mappings you can set values based on a region. You can create a mapping that uses the region name as a key and contains the values you want to specify for each specific region.
The optional Outputs section declares output values that you can import into other stacks (to create cross-stack references), return in response (to describe stack calls), or view on the AWS CloudFormation console
The optional Conditions section contains statements that define the circumstances under which entities are created or configured
- The optional Transform section specifies one or more macros that AWS CloudFormation uses to process your template
- The transform section can be used to reference additional code stored in S3, such as Lambda code or reusable snippets of CloudFormation code
- The
AWS::Serverlesstransform specifies the version of the AWS Serverless Application Model (AWS SAM) to use - This model defines the AWS SAM syntax that you can use and how AWS CloudFormation processes it
- The
AWS::Includetransform works with template snippets that are stored separately from the main AWS CloudFormation template
- With the DependsOn attribute you can specify that the creation of a specific resource follows another
- When you add a DependsOn attribute to a resource, that resource is created only after the creation of the resource specified in the DependsOn attribute
- Use a WaitCondition to ensure resources are ready
- You can use a wait condition for situations like the following:
- To coordinate stack resource creation with configuration actions that are external to the stack creation
- To track the status of a configuration process
Creation Policy
- Use the CreationPolicy attribute when you want to wait on resource configuration actions before stack creation proceeds
- You can associate the CreationPolicy attribute with a resource to prevent its status from reaching create complete until AWS CloudFormation receives a specified number of success signals or the timeout period is exceeded
- To signal a resource, you can use the cfn-signal helper script or SignalResource API
- AWS CloudFormation publishes valid signals to the stack events so that you track the number of signals sent
- The following CloudFormation resources support creation policies:
AWS::AutoScaling::AutoScalingGroupAWS::EC2::InstanceAWS::CloudFormation::WaitCondition
Deletion Policy
- With the DeletionPolicy attribute you can preserve or (in some cases) backup a resource when its stack is deleted
- You specify a DeletionPolicy attribute for each resource that you want to control
- If a resource has no DeletionPolicy attribute, AWS CloudFormation deletes the resource by default
- Deletion policies can be specified as:
DeletionPolicy=Retain– preserves the resourcesDeletionPolicy=Snapshot– takes a snapshot (e.g. for EC2, ElastiCache, RDS)DeletionPolicy=Delete– default, attempts to delete the resources
UpdatePolicy and UpdateReplacePolicy
- Use the UpdatePolicy attribute to specify how AWS CloudFormation handles updates to the following resources:
AWS::AutoScaling::AutoScalingGroupAWS::ElastiCache::ReplicationGroupAWS::Elasticsearch::DomainAWS::Lambda::Alias
- Use the UpdateReplacePolicy attribute to retain or (in some cases) backup the existing physical instance of a resource when it is replaced during a stack update operation
Custom Resources
Custom resources enable you to write custom provisioning logic in templates that AWS CloudFormation runs anytime you create, update (if you changed the custom resource), or delete stacks
- By creating a custom resource backed by an AWS Lambda function, you have the flexibility to define and orchestrate multiple AWS services as a single resource within your CloudFormation stack.
- The custom Lambda function can handle the logic for creating and deleting the resources across multiple services in the desired order and configuration.
Deploying CloudFormation templates
- Manual way:
- Editing templates in the CloudFormation Designer
- Using the console to input parameters, etc
- Automated way:
- Editing templates in a YAML file
- Using the AWS CLI (Command Line Interface) to deploy the templates
- Recommended way when you fully want to automate your flow
Intrinsic Functions
Fn::Ref(!Ref)- Returns the value of the specified parameter or resource
- When you specify a parameter’s logical name, it returns the value of the parameter
- When you specify a resource’s logical name, it returns a value that you can typically use to refer to that resource, such as a physical ID
Fn::GetAtt- Returns the value of an attribute from a resource in the template
- Full syntax:
Fn::GetAtt: [ logicalNameOfResource, attributeName ] - Short form:
!GetAtt logicalNameOfResource.attributeName
Fn::FindInMap- Returns the value corresponding to keys in a two-level map that is declared in the Mappings section
- Full syntax:
Fn::FindInMap: [ MapName, TopLevelKey, SecondLevelKey ] - Short form:
!FindInMap [ MapName, TopLevelKey, SecondLevelKey ]
Fn::ImportValueFn::JoinFn::Sub- Condition Functions (
Fn::If,Fn::Not,Fn::Equals,Fn::And,Fn::Or) - ...
Rollbacks and Stack Creation Failures
- Stack creation failures:
- By default everything will be deleted
- Can modify the OnFailure attribute for a stack
- OnFailure must be one of:
DO_NOTHING– leaves the resources in place (good for troubleshooting)ROLLBACK– rolls the stack backDELETE– deletes the resources
- Stack update failures:
- A stack goes into the UPDATE_ROLLBACK_FAILED state when AWS CloudFormation cannot roll back all changes during an update
- The stack will automatically roll back to the previous known working state
- When a stack is in the UPDATE_ROLLBACK_FAILED state, you can continue to roll it back to a working state (UPDATE_ROLLBACK_COMPLETE)
- You can't update a stack that is in the UPDATE_ROLLBACK_FAILED state
- However, if you can continue to roll it back, you can return the stack to its original settings and then try to update it again
Stacks
- Deployed resources based on templates
- You create, update and delete stacks using templates
- Stacks are deployed through the Management Console, CLI or APIs
- Stack creation errors:
- Automatic rollback on error is enabled by default
- You will be charged for resources provisioned even if there is an error
Nested stacks
- Nested stacks are stacks as part of other stacks
- They allow you to isolate repeated patterns / common components in separate stacks and call them from other stacks
- Example:
- Load Balancer configuration that is re-used
- Security Group that is re-used
- Nested stacks are considered best practice
- To update a nested stack, always update the parent (root stack)
Cross vs Nested Stacks
- Helpful when stacks have different lifecycles
- Use Outputs Export and
Fn::ImportValue - When you need to pass export values to many stacks (VPC Id, etc...)
- Helpful when components must be re-used
- Ex: re-use how to properly configure an Application Load Balancer
- The nested stack only is important to the higher level stack (it’s not shared)
StackSets
- Create, update, or delete stacks across multiple accounts and regions with a single operation
- An administrator account is the AWS account in which you create StackSets
- A target account is the account into which you create, update, or delete one or more stacks in your stack set
- When you update a stack set, all associated stack instances are updated throughout all accounts and regions
- StackSets can be targeted to specific organizational units (OUs) within AWS Organizations
Tip
Helper Script(cfn-init)
cfn-initis a helper script that can be used to retrieve and interpret resource metadata- The cfn-init helper script reads template metadata from the
AWS::CloudFormation::Initkey and acts accordingly to:- Fetch and parse metadata from AWS CloudFormation
- Install packages
- Write files to disk
- Enable/disable and start/stop services
- Logs go to
/var/log/cfn-init.log - To install the applications the UserData property and Metadata property can be added to a template
- The cfn-signal helper script signals AWS CloudFormation to indicate whether Amazon EC2 instances have been successfully created or updated
- After installing software on EC2 instances, you can signal AWS CloudFormation when those software applications are ready
- You use the cfn-signal script in conjunction with a CreationPolicy or an Auto Scaling group with a WaitOnResourceSignals update policy
- In the UserData property, the template runs the cfn-signal script to send a success signal with an exit code if all the services are configured and started successfully
- Troubleshooting errors:
- Make sure the AMI has the CloudFormation helper scripts included
- Check that the cfn-init and cfn-signal commands have run successfully
CloudFormation Drift
- CloudFormation allows you to create infrastructure
- But it doesn’t protect you against manual configuration changes
- How do we know if our resources have drifted? -> Cloudformation drift
AWS Elastic Beanstalk
Overview
- Elastic Beanstalk is a developer centric view of deploying an application on AWS
- We still have full control over the configuration
- Platform as a Service (PaaS)
- Automatically handles capacity provisioning, load balancing, scaling, application health monitoring, instance configuration, ...
- Just the application code is the responsibility of the developer
- Beanstalk is free but you pay for the underlying instances
- Supports Java, .NET, PHP, Node.js, Python, Ruby, Go, and Docker web applications
- Supports the following languages and development stacks:
- Apache Tomcat for Java applications
- Apache HTTP Server for PHP applications
- Apache HTTP Server for Python applications
- Nginx or Apache HTTP Server for Node.js applications
- Passenger or Puma for Ruby applications
- Microsoft IIS 7.5, 8.0, and 8.5 for .NET applications
- Java SE
- Docker
- Go
Components
- Application:
- Contain environments, environment configurations, and application versions
- You can have multiple application versions held within an application
- Application Version:
- A specific reference to a section of deployable code
- The application version will point typically to an Amazon S3 bucket containing the code
- Environment:
- An application version that has been deployed on AWS resources
- The resources are configured and provisioned by AWS Elastic Beanstalk
- The environment is comprised of all the resources created by Elastic Beanstalk and not just an EC2 instance with your uploaded code
Web Servers and Workers
- Determines how Elastic Beanstalk provisions resources based on what the application is designed to do
- Consists of Web Servers and Workers:
- Web servers are standard applications that listen for and then process HTTP requests, typically over port 80
- Workers are specialized applications that have a background processing task that listens for messages on an Amazon SQS queue
- Workers should be used for long-running tasks
Deployment Options for Updates
- All at once (deploy all in one go)
- Deploys the new version to all instances simultaneously
- All of your instances are out of service while the deployment takes place
- Fastest deployment
- Good for quick iterations in development environment
- You will experience an outage(downtime) while the deployment is taking place - not ideal for mission-critical systems
- If the update fails, you need to roll back the changes by re- deploying the original version to all of your instances
- No additional cost
- Rolling
- Update a few instances at a time (batch), and then move onto the next batch once the first batch is healthy (downtime for 1 batch at a time)
- Application is running both versions simultaneously
- Each batch of instances is taken out of service while the deployment takes place
- Your environment capacity will be reduced by the number of instances in a batch while the deployment takes place
- Not ideal for performance-sensitive systems
- If the update fails, you need to perform an additional rolling update to roll back the changes.
- No additional cost
- Long deployment time
- Rolling with additional batches
- Like Rolling but launches new instances in a batch ensuring that there is full availability
- Application is running at capacity
- Can set the batch size
- Application is running both versions simultaneously
- Small additional cost
- Additional batch is removed at the end of the deployment
- Longer deployment
- Good for production environments
- Immutable
- Launches new instances in a new ASG and deploys the version update to these instances before swapping traffic to these instances once healthy
- Zero downtime
- New code is deployed to new instances using an ASG
- High cost as double the number of instances running during updates
- Longest deployment
- Quick rollback in case of failures
- Great for production environments
- Blue / Green
- Not a "direct feature" of Elastic Beanstalk
- Zero downtime and release facility
- Create a new "stage" environment and v1 deploy v2 there
- The new environment (green) can be validated independently and roll back if issues
- Route 53 can be setup using weighted policies to redirect a little bit of traffic to the stage environment
- Using Beanstalk "swap URLs" when done with the environment test
Traffic Splitting
- Canary Testing
- New application version is deployed to a temporary ASG with the same capacity
- A small % of traffic is sent to the temporary ASG for a configurable amount of time
- Deployment health is monitored
- If there’s a deployment failure, this triggers an automated rollback (very quick)
- No application downtime
- New instances are migrated from the temporary to the original ASG
- Old application version is then terminated
Tip
Miners would take a canary into the mines with them to determine if the air held dangerous levels of toxic gases. The idea was that the bird had a faster breathing rate than humans and would show signs of the presence of toxic gases sooner than humans would. If the canary died, the miners would know that they needed to evacuate the mine.
Extensions
- A zip file containing our code must be deployed to Elastic Beanstalk
- All the parameters set in the UI can be configured with code using files
- Requirements:
- in the
.ebextensions/directory in the root of source code - YAML / JSON format
.configextensions (example: logging.config)- Able to modify some default settings using: option_settings
- Ability to add resources such as RDS, ElastiCache, DynamoDB, etc...
- in the
- Resources managed by .ebextensions get deleted if the environment goes away
Cloning
- Clone an environment with the exact same configuration
- Useful for deploying a "test" version of your application
- All resources and configuration are preserved:
- Load Balancer type and configuration
- RDS database type (but the data is not preserved)
- Environment variables
- After cloning an environment, you can change settings
Migration: Load Balancer
- After creating an Elastic Beanstalk environment, you cannot change the Elastic Load Balancer type (only the configuration)
- To migrate:
- create a new environment with the same configuration except LB (can’t clone)
- deploy your application onto the new environment
- perform a CNAME swap or Route 53 update
AWS Cloud9
- AWS Cloud9 is a cloud IDE (Integrated Development Environment) for writing, running and debugging code
- Allows for code collaboration in real-time (pair programming)
AWS Systems Manager (SSM)
- Helps you manage your EC2 and On-Premises systems at scale
- Another Hybrid AWS service
- Get operational insights about the state of your infrastructure
- Suite of 10+ products
- Most important features are:
- Patching automation for enhanced compliance
- Run commands across an entire fleet of servers
- Store parameter configuration with the SSM Parameter Store
- Works for both Windows and Linux OS
AWS OpsWorks
- Chef & Puppet help you perform server configuration automatically, or repetitive actions
- They work great with EC2 & On-PremisesVM
- AWS OpsWorks = Managed Chef & Puppet
- It’s an alternative to AWS SSM
- Only provision standard AWS resources: EC2 Instances, Databases, Load Balancers, EBS volumes...
- Updates include patching, updating, backup, configuration and compliance management
CI/CD
AWS CodeCommit
- Source-control service that hosts Git-based repositories -> Makes it easy to collaborate with others on code
- The code changes are automatically versioned
- Benefits:
- Fully managed
- Scalable & highly available
- Private, Secured, Integrated with AWS
- Authentication
- SSH Keys – AWS Users can configure SSH keys in their IAM Console
- HTTPS – with AWS CLI Credential helper or Git Credentials for IAM user
- Authorization
- IAM policies to manage users/roles permissions to repositories
- Encryption
- Encrypted in transit (can only use HTTPS or SSH – both secure)
- Repositories are automatically encrypted at rest using AWS KMS
- Cross-account Access
- Do NOT share your SSH keys or your AWS credentials
- Use an IAM Role in your AWS account and use AWS STS (AssumeRole API)
AWS CodeBuild
- A fully managed continuous integration (CI) service
- Continuous scaling (no servers to manage or provision – no build queue)
- Compile source code, run tests, produce software packages, ...
- Alternative to other build tools (e.g., Jenkins)
- Charged per minute for compute resources (time it takes to complete the builds)
- Leverages Docker under the hood for reproducible builds
- Use prepackaged Docker images or create your own custom Docker image
- Security:
- Integration with KMS for encryption of build artifacts
- IAM for CodeBuild permissions,and VPC for network security
- AWS CloudTrail for API calls logging
- Build instructions: Code file buildspec.yml or insert manually in Console
- Output logs can be stored in Amazon S3 & CloudWatch Logs
- Use CloudWatch Metrics to monitor build statistics
- Use CloudWatch Events to detect failed builds and trigger notifications
- Use CloudWatch Alarms to notify if you need "thresholds" for failures
- Build Projects can be defined within CodePipeline or CodeBuild
buildspec.yml
- buildspec.yml file must be at the root of your code
- env – define environment variables
- variables – plaintext variables
- parameter-store – variables stored in SSM Parameter Store
- secrets-manager – variables stored in AWS Secrets Manager
- phases – specify commands to run:
- install – install dependencies you may need for your build
- pre_build – final commands to execute before build
- Build – actual build commands
- post_build – finishing touches (e.g., zip output)
- artifacts – what to upload to S3 (encrypted with KMS)
- cache – files to cache (usually dependencies) to S3 for future build speedup
AWS CodeDeploy
- We want to deploy our application automatically
- Works with EC2 Instances
- Works with On-Premises Servers
- Hybrid service
- Servers / Instances must be provisioned and configured ahead of time with the CodeDeploy Agent
Primary Components
- Application – a unique name functions as a container (revision, deployment configuration, ...)
- Compute Platform – EC2/On-Premises, AWSLambda, or AmazonECS
- Deployment Configuration – a set of deployment rules for success/failure
- EC2/On-premises – specify the minimum number of healthy instances for the deployment
- AWS Lambda or Amazon ECS – specify how traffic is routed to your updated versions
- Deployment Group - group of tagged EC2 instances (allows to deploy gradually, or dev, test, prod...)
- Deployment Type – method used to deploy the application to a Deployment Group
- In-place Deployment – supports EC2/On-Premises
- Blue/Green Deployment – suppor ts EC2 instances only, AWS Lambda, and Amazon ECS
- IAM Instance Profile – give EC2 instances the permissions to access both S3 / GitHub
- Application Revision – application code +
appspec.ymlfile - Service Role – an IAM Role for CodeDeploy to perform operations on EC2 instances, ASGs, ELBs...
- Target Revision – the most recent revision that you want to deploy to a Deployment Group
appspec.yml
- files – how to source and copy from S3 / GitHub to filesystem
- source
- destination
- hooks – set of instructions to do to deploy the new version (hooks can have timeouts), the order is:
- ApplicationStop
- DownloadBundle
- BeforeInstall
- Install
- AfterInstall
- ApplicationStart
- ValidateService <- important!!
- BeforeAllowTraffic
- AllowTraffic
- AfterAllowTraffic
Deployment Configuration
- Configurations:
- One At A Time – one EC2 instance at a time, if one instance fails then deployment stops
- Half At A Time – 50%
- All At Once – quick but no healthy host, downtime. Good for dev
- Custom – min. healthy host = 75%
- Failures:
- EC2 instances stay in "Failed" state
- New deployments will first be deployed to failed instances
- To rollback, redeploy old deployment or enable automated rollback for failures
- Deployment Groups:
- A set of tagged EC2 instances
- Directly to an ASG
- Mix of ASG / Tags so you can build deployment segments
- Customization in scripts with DEPLOYMENT_GROUP_NAME environment variables
Deploy to an ASG
- In-place Deployment
- Updates existing EC2 instances
- Newly created EC2 instances by an ASG will also get automated deployments
- Blue/Green Deployment
- A new Auto-Scaling Group is created (settings are copied)
- Choose how long to keep the old EC2 instances (old ASG)
- Must be using an ELB
AWS CodePipeline
- Orchestrate the different steps to have the code automatically pushed to production
- Code => Build => Test => Provision => Deploy
- Basis for CICD (Continuous Integration & Continuous Delivery)
- Benefits:
- Fully managed, compatible with CodeCommit, CodeBuild, CodeDeploy, ElasticBeanstalk, CloudFormation, GitHub, 3rd-party services (GitHub...) & custom plugins...
- Fast delivery & rapid updates
- Artifacts
- Each pipeline stage can create artifacts
- Artifacts stored in an S3 bucket and passed on to the next stage
AWS CodeArtifact
- Software packages depend on each other to be built (also called code dependencies), and new ones are created
- Storing and retrieving these dependencies is called artifact management
- Traditionally you need to setup your own artifact management system
- CodeArtifact is a secure, scalable, and cost-effective artifact management for software development
- Works with common dependency management tools such as Maven, Gradle, npm, yarn, twine, pip, and NuGet
- Developers and CodeBuild can then retrieve dependencies straight from CodeArtifact
AWS CodeStar
- An integrated solution that groups: GitHub, CodeCommit, CodeBuild, CodeDeploy, CloudFormation, CodePipeline, CloudWatch, ...
- Quickly create "CICD-ready" projects for EC2, Lambda, Elastic Beanstalk
- Supported languages: C#, Go, Java, Node.js, PHP, Python, Ruby
- Issue tracking integration with JIRA / GitHub Issues
- Ability to integrate with Cloud9 to obtain a web IDE (not all regions)
- One dashboard to view all your components
- Free service, pay only for the underlying usage of other services
- Limited Customization
Amazon CodeGuru
- An ML-powered service for automated code reviews and application performance recommendations
- Provides two functionalities
- CodeGuru Reviewer: automated code reviews for static code analysis (development)
- CodeGuru Profiler: visibility/recommendations about application performance during runtime (production)
Cloud Integration & Messaging
Amazon SQS
Note
SQS queue cannot be put in a VPC subnet
SQS does not have a security group
Standard Queue
Oldest offering, Fully managed service, used to decouple applications
- Attributes:
- Unlimited throughput, unlimited number of messages in queue
- Default retention of messages: 4 days; maximum of 14 days
- Low latency (<10 ms on publish and receive)
- Limitation of 256KB per message sent
- Can have duplicate messages (at least once delivery, occasionally)
- Can have out of order messages (best effort ordering)
Producing Messages
- Produced to SQS using the SDK (
SendMessageAPI) - The message is persisted in SQS until a consumer deletes it
- Message retention: default 4 days, up to 14 days
- SQS standard: unlimited throughput
Consuming Messages
- Consumers (running on EC2 instances, servers, or AWS Lambda)...
- Poll SQS for messages (receive up to 10 messages at a time)
- Process the messages (example: insert the message into an RDS database)
- Delete the messages using the DeleteMessage API
Multiple EC2 Instances Consumers
- Consumers receive and process messages in parallel
- At least once delivery
- Best-effort message ordering
- Consumers delete messages after processing them
- We can scale consumers horizontally to improve throughput of processing
Security
- Encryption:
- In-flight encryption using HTTPS API
- At-rest encryption using KMS keys
- Client-side encryption if the client wants to perform encryption/decryption itself
- Access Controls: IAM policies to regulate access to the SQS API
- SQS Access Policies (similar to S3 bucket policies)
- Useful for cross-account access to SQS queues
- Useful for allowing other services (SNS, S3...) to write to an SQS queue
Message Visibility Timeout
- After a message is polled by a consumer, it becomes invisible to other consumers
- By default, the "message visibility timeout" is 30 seconds -> That means the message has 30 seconds to be processed
- Min: 0 seconds; Max: 12 hours
- After the message visibility timeout is over, the message is "visible" in SQS
- If a message is not processed within the visibility timeout, it will be processed twice
- A consumer could call the
ChangeMessageVisibilityAPI to get more time - If visibility timeout is high (hours), and consumer crashes, re-processing will take time
- If visibility timeout is too low (seconds), we may get duplicates
Dead Letter Queue
- If a consumer fails to process a message within the Visibility Timeout... the message goes back to the queue!
- We can set a threshold of how many times a message can go back to the queue
- After the
Maximum Receivesthreshold is exceeded, the message goes into a dead letter queue (DLQ) - The main task of a dead-letter queue is handling message failure -> Useful for debugging!
- It is not a queue type, it is a
standardorFIFOqueue that has been specified as a dead-letter queue in the configuration of another standard or FIFO queue- DLQ of a FIFO queue must also be a FIFO queue
- DLQ of a Standard queue must also be a Standard queue
- Make sure to process the messages in the DLQ before they expire: Good to set a retention of 14 days in the DLQ
Delay Queue
- Delay a message (consumers don’t see it immediately) up to 15 minutes
- Default is 0 seconds (message is available right away)
- Can set a default at queue level
- Can override the default on send using the
DelaySecondsparameter
Long Polling VS Short Polling
Long polling waits for the
WaitTimeSecondsand eliminates empty responses
Short polling checks a subset of servers and may not return all messages
- When a consumer requests messages from the queue, it can optionally "wait" for messages to arrive if there are none in the queue -> This is called Long Polling
- LongPolling decreases the number of API calls made to SQS while increasing the efficiency and latency of your application
- The wait time can be between 1 sec to 20 sec (20 sec preferable)
- Long Polling is preferable to Short Polling
- Long polling can be enabled at the queue level or at the API level using
WaitTimeSeconds - SQS
Short pollingreturns immediately (even if the message queue is empty)
Extended Client
- Message size limit is 256KB, how to send large messages, e.g. 1GB? => Using the SQS Extended Client (Java Library)
- Producer send small metadata message to SQS Queue, at the meantime send large message to S3
- Consumer retrieve small metadata message from SQS Quese, and retrieve large message from S3
Useful APIs
- CreateQueue (MessageRetentionPeriod), DeleteQueue
- PurgeQueue: delete all the messages in queue
- SendMessage (DelaySeconds), ReceiveMessage, DeleteMessage
- MaxNumberOfMessages: default 1, max 10 (for ReceiveMessage API)
- ReceiveMessageWaitTimeSeconds: Long Polling
- ChangeMessageVisibility: change the message timeout
FIFO Queue
FIFO: First In First Out (ordering of messages in the queue)
- Limited throughput: 300 msg/s without batching, 3000 msg/s with Exactly-once send capability (by removing duplicates)
- Messages are processed in order by the consumer
- FIFO queues require the
Message Group IDandMessage Deduplication IDparameters to be added to messages - Message Group ID:
- The tag that specifies that a message belongs to a specific message group Messages that belong to the same message group are guaranteed to be processed in a FIFO manner
- You can have as many consumers as
MessageGroupIDfor you FIFO queues
- Message Deduplication ID:
- The token used for deduplication of messages within the deduplication interval
FIFO – Deduplication
- De-duplication interval is 5 minutes
- Two de-duplication methods:
- Content-based deduplication: will do a SHA-256 hash of the message body
- Explicitly provide a
MessageDeduplicationID
Amazon Kinesis
Kinesis = real-time big data streaming
Overview
- Managed service to collect, process, and analyze real-time streaming data at any scale
- Ingest real-time data such as: Application logs, Metrics, Website clickstreams, IoT telemetry data…
Kinesis Data Streams: capture, process, and store data streamsKinesis Data Firehose: load data streams into AWS data storesKinesis Data Analytics: analyze data streams with SQL or Apache FlinkKinesis Video Streams: capture, process, and store video streams
Kinesis Data Streams - Overview
- Retention between 1 day to 365 days
- Ability to reprocess (replay) data
- Once data is inserted in Kinesis, it can’t be deleted (immutability)
- Data that shares the same partition goes to the same shard (ordering)
- Producers: AWS SDK, Kinesis Producer Library (KPL), Kinesis Agent
- Consumers:
- Write your own: Kinesis Client Library (KCL), AWS SDK
- Managed: AWS Lambda, Kinesis Data Firehose, Kinesis Data Analytics
Kinesis Data Streams – Capacity Modes
- Provisioned mode:
- You choose the number of shards provisioned, scale manually or using API
- Each shard gets 1MB/s in (or 1000 records per second)
- Each shard gets 2MB/s out (classic or enhanced fan-out consumer)
- You pay per shard provisioned per hour
- On-demand mode:
- No need to provision or manage the capacity
- Default capacity provisioned (4 MB/s in or 4000 records per second)
- Scales automatically based on observed throughput peak during the last 30 days
- Pay per stream per hour & data in/out per GB
Kinesis Data Streams - Security
- Control access / authorization using IAM policies
- Encryption in flight using HTTPS endpoints
- Encryption at rest using KMS
- You can implement encryption/decryption of data on client side
- VPC Endpoints available for Kinesis to access within VPC
- Monitor API calls using CloudTrail
Kinesis Data Streams - Producers
Puts data records into data streams
- Data record consists of:
- Sequence number (unique per partition-key within shard)
- Partition key (must specify while put records into stream)
- Data blob (up to 1 MB)
- Producers:
- AWS SDK: simple producer
- Kinesis Producer Library (KPL): A Java library that helps read record from a Kinesis Data Stream with distributed applications sharing the read workload
- Kinesis Agent: monitor log files
- Write throughput: 1 MB/sec or 1000 records/sec per shard
- Use batching with PutRecords API to reduce costs & increase throughput
Kinesis Data Streams Consumers
Get data records from data streams and process them
- AWS Lambda
- Kinesis Data Analytics
- Kinesis Data Firehose
- Custom Consumer (AWS SDK) – Classic or Enhanced Fan-Out
- Kinesis Client Library (KCL): library to simplify reading from data stream
Kinesis Data Firehose
- Fully Managed Service, no administration, automatic scaling, serverless
- AWS: Redshift / Amazon S3 / ElasticSearch
- 3rd party partner: Splunk / MongoDB / DataDog / NewRelic / ...
- Custom: send to any HTTP endpoint
- Pay for data going through Firehose
- Near Real Time
- 60 seconds latency minimum for non full batches
- Or minimum 1MB of data at a time
- Supports many data formats, conversions, transformations, compression
- Supports custom data transformations using AWS Lambda
- Can send failed or all data to a backup S3 bucket
- Kinesis Data Firehose Destinations:
- RedShift (via an intermediate S3 bucket)
- Elasticsearch
- Amazon S3
- Splunk
- Datadog
- MongoDB
- New Relic
- HTTP Endpoint
Kinesis Data Analytics (SQL application)
- Real-time analytics on Kinesis Data Streams & Firehose using SQL
- Add reference data from Amazon S3 to enrich streaming data
- Fully managed, no servers to provision
- Automatic scaling
- Pay for actual consumption rate
- Output:
- Kinesis Data Streams: create streams out of the real-time analytics queries
- Kinesis Data Firehose: send analytics query results to destinations
- Lambda
- Use cases:
- Time-series analytics
- Real-time dashboards
- Real-time metrics
Amazon SNS
Amazon SNS is a highly available, durable, secure, fully managed pub/sub messaging service
- Amazon SNS provides topics for high-throughput, push-based, many-to-many messaging
- Multiple recipients can be grouped using Topics
- A topic is an “access point” for allowing recipients to dynamically subscribe for identical copies of the same notification
- One topic can support deliveries to multiple endpoint types
- The "event publishers" only sends message to one SNS topic
- As many "event subscribers"(subscriptions) as we want to listen to the SNS topic notifications
- Each subscriber to the topic will get all the messages(note: new feature to filter messages)
- Up to 12,500,000 subscriptions per topic, 100,000 topics limit
- Endpoints include:
- Amazon SQS queues
- AWS Lambda functions
- HTTP(S) webhooks
- Mobile push
- SMS
How to publish
- Topic Publish (using the SDK)
- Create a topic
- Create a/many subscription(s)
- Publish to the topic
- Direct Publish (for mobile apps SDK)
- Create a platform application
- Create a platform endpoint
- Publish to the platform endpoint
- Works with Google GCM, Apple APNS, Amazon ADM...
Security
- Encryption:
- In-flight encryption using HTTPS API
- At-rest encryption using KMS keys
- Client-side encryption if the client wants to perform encryption/decryption itself
- Access Controls: IAM policies to regulate access to the SNS API
- SNS Access Policies (similar to S3 bucket policies)
- Useful for cross-account access to SNS topics
- Useful for allowing other services ( S3...) to write to an SNS topic
Message Filtering
- JSON policy used to filter messages sent to SNS topic’s subscriptions
- If a subscription doesn’t have a filter policy, it receives every message
SQS vs SNS vs Kinesis
- Consumer "pull data"
- Data is deleted after being consumed
- Can have as many workers (consumers) as we want
- No need to provision throughput
- Ordering guarantees only on FIFO queues
- Individual message delay capability
- Push data to many subscribers
- Up to 12,500,000 subscribers
- Data is not persisted (lost if not delivered)
- Pub/Sub
- Up to 100,000 topics
- No need to provision throughput
- Integrates with SQS for fan- out architecture pattern
- FIFO capability for SQS FIFO
- Standard: pull data(2 MB per shard)
- Enhanced-fan out: push data(2 MB per shard per consumer)
- Possibility to replay data
- Meant for real-time big data, analytics and ETL
- Ordering at the shard level
- Data expires after X days
- Provisioned mode or ondemand capacity mode
Amazon MQ
Amazon MQ: managed Apache ActiveMQ
- SQS, SNS are "cloud-native" services, and they’re using proprietary protocols from AWS.
- Traditional applications running from on-premise may use open protocols such as: MQTT, AMQP, STOMP, Openwire, WSS
- When migrating to the cloud, instead of re-engineering the application to use SQS and SNS, we can use Amazon MQ
- Amazon MQ is a managed message broker service for RabbitMQ & ActiveMQ
- Amazon MQ doesn’t "scale" as much as SQS / SNS
- Amazon MQ runs on a dedicated machine (not serverless)
- Amazon MQ has both queue feature (~SQS) and topic features (~SNS)
Cloud Monitoring, Logging, and Auditing
Tip
Amazon's five phases of the monitoring process:
- Generation
- Aggregation
- Real-time processing and alarming
- Storage
- Analysis
CloudWatch Namespaces
- A namespace is a container for CloudWatch metrics
- Metrics in different namespaces are isolated from each other
- You must specify a namespace for each data point you publish to CloudWatch
- You can specify a namespace name when you create a metric
CloudWatch Metrics
- CloudWatch provides metrics for every services in AWS
- Metric is a variable to monitor (CPUUtilization, NetworkIn...)
- Metrics belong to namespaces
- Dimension is an attribute of a metric (instance id, environment, etc...)
- Up to 10 dimensions per metric
- Metrics exist within a region
- Metrics cannot be deleted but automatically expire after 15 months
- Metrics are uniquely defined by a name, a namespace, and zero or more dimensions
- Time stamps can be up to two weeks in the past and up to two hours into the future
- Can create CloudWatch dashboards of metrics
Tip
The procstat plugin enables you to collect metrics from individual processes.
EC2 Detailed monitoring
- EC2 instance metrics have metrics "every 5 minutes"(free)
- With detailed monitoring (for a cost), you get data "every 1 minute"
- Use detailed monitoring if you want to scale faster for your ASG!
- Note: EC2 Memory usage is by default not pushed (must be pushed from inside the instance as a custom metric)
- Unified CloudWatch Agent sends system-level metrics for EC2 and on-premises servers
Custom Metrics
- Possibility to define and send your own custom metrics to CloudWatch
- Example: memory (RAM) usage, disk space, number of logged in users ...
- Use API call
PutMetricData - Ability to use dimensions (attributes) to segment metrics
- Instance.id
- Environment.name
- Metric resolution (StorageResolution API parameter – two possible value):
- Standard: 1 minute (60 seconds)
- High Resolution: 1/5/10/30 second(s) – Higher cost
- Important: Accepts metric data points two weeks in the past and two hours in the future
Example
Example of CloudWatch agent configuration file:
Tip
In custom metrics, the --dimensions parameter is common.
A dimension further clarifies what the metric is and what data it stores.
You can have up to 30 dimensions assigned to one metric, and each dimension is defined by a name and value pair.
Retention Periods
CloudWatch metrics are retained for 15 months with the following retention periods:
- Custom, subminute metrics are aggregated to minute metrics after 3 hours.
- One-minute metrics are aggregated to 5-minute metrics after 15 days.
- Five-minute metrics are aggregated to hourly metrics after 63 days.
- Hourly metrics aggregates are discarded after 455 days(15 months).
Note
While the default metrics retention period is 15 months, the retention of logs in CloudWatch is indefinite.
CloudWatch API Actions(Metrics)
GetMetricData- Retrieve as many as 500 different metrics in a single request
PutMetricData- Publishes metric data points to Amazon CloudWatch
- CloudWatch associates the data points with the specified metric
- If the specified metric does not exist, CloudWatch creates the metric
GetMetricStatistics- Gets statistics for the specified metric
- CloudWatch aggregates data points based on the length of the period that you specify
- Maximum number of data points returned from a single call is 1,440
Unified CloudWatch Agent
- The unified CloudWatch agent enables you to do the following:
- Collect internal system-level metrics from Amazon EC2 instances across operating systems
- Collect system-level metrics from on-premises servers
- Retrieve custom metrics from your applications or services using the StatsD and collectd protocols
- Collect logs from Amazon EC2 instances and on-premises servers (Windows / Linux)
- Agent must be installed on the server
- Can be installed on:
- Amazon EC2 instances
- On-premises servers
- Linux, Windows Server, or macOS
- You can use the following installation methods:
- Command line
- AWS Systems Manager
- AWS CloudFormation
- Installation Process:
- Create IAM roles to enable metric collection
- Download the agent package
- Update CloudWatch agent configuration file
- Start the agent
Note
- When starting the agent, you must attach the IAM role (EC2), or specify a named profile (on-premises)
- You can optionally integrate with AWS Systems Manager
- The
procstatplugin enables you to collect metrics from individual processes. It is supported on Linux servers and on servers running Windows Server 2012 or later
CloudWatch Logs
CloudWatch Logs can send logs to:
- Amazon S3 (exports)
- Kinesis Data Streams
- Kinesis Data Firehose
- AWS Lambda
- ElasticSearch
Features
- CloudWatch
Logs Insightscan be used to interactively search and analyze log data - Monitor applications and systems using log data
- Create alarms based on API activity captured by
CloudTrail - By default, logs are kept indefinitely and never expire
- You can adjust the retention policy for each log group, keeping the indefinite retention, or choosing a retention period between 10 years and one day
- CloudWatch Logs can be used to log information about the DNS queries that
Route 53receives
Concepts
- Log events – a record of activity recorded by a monitored resource
- Log streams – a sequence of log events that share the same source
- Log groups – groups of log streams that share retention, monitoring, and access control settings
- Metric filters – used to extract metric observations from ingested events and transform them to data points in a CloudWatch metric
- Retention settings – specify how long log events are kept in CloudWatch Logs
Sources
- SDK, CloudWatch Logs Agent, CloudWatch Unified Agent
- Elastic Beanstalk: collection of logs from application
- ECS: collection from containers
- AWS Lambda: collection from function logs
- VPC Flow Logs:VPC specific logs
- API Gateway
- CloudTrail based on filter
- Route53: Log DNS queries
Namespaces and Dimensions
- All data in CloudWatch is recorded with a specific namespace format.
- Default metrics are formatted as Service:Metric. For example, EC2:CPUUtilization.
- Dimensions are
key:valuepairs assigned to metrics to allow for a more granular analysis of those metrics within a specific namespace. - CloudWatch allows you to create 10 dimensions for each metric.
Metric Filter & Insights
- CloudWatch Logs can use filter expressions
- Metric filters can be used to trigger CloudWatch alarms
CloudWatch Logs Insightscan be used to query logs and add queries to CloudWatch Dashboards
S3 Export
- Log data can take up to 12 hours to become available for export
- The API call is
CreateExportTask - Not near-real time or real-time... use Logs Subscriptions instead
Logs for EC2
- By default, no logs from your EC2 machine will go to CloudWatch
- You need to run a CloudWatch agent on EC2 to push the log files you want
- Make sure IAM permissions are correct
- The CloudWatch log agent can be setup on-premises too
Logs Agent
- For virtual servers (EC2 instances, on-premises servers...)
- CloudWatch Logs Agent
- Old version of the agent
- Can only send to CloudWatch Logs
CloudWatch Alarms
- Alarms are used to trigger notifications for any metric
- Alarms targets:
- Auto Scaling: increase or decrease EC2 instances "desired" count
- EC2 Actions: stop, terminate, reboot or recover an EC2 instance
- SNS notifications: send a notification into an SNS topic
- Various options (sampling, %, max, min, etc...)
- Can choose the period on which to evaluate an alarm -> Example: create a billing alarm on the CloudWatch Billing metric
- Two types of alarms
Metric alarm– performs one or more actions based on a single metricComposite alarm– uses a rule expression and takes into account multiple alarms
- Metric alarm states:
- OK – Metric is within a threshold
- ALARM – Metric is outside a threshold
- INSUFFICIENT_DATA – not enough data
- Period:
- Length of time in seconds to evaluate the metric
- High resolution custom metrics: 10 sec, 30 sec or multiples of 60 sec
Note
You can create a custom metric using the API or CLI command set-alarm-state
CloudWatch Events
- Event Pattern: Intercept events from AWS services (Sources)
- Example sources: EC2 Instance Start, CodeBuild Failure, S3, Trusted Advisor
- Can intercept any API call with CloudTrail integration
- Schedule or Cron (example: create an event every 4 hours)
- A JSON payload is created from the event and passed to a target...
- Compute: Lambda, Batch, ECS task
- Integration: SQS, SNS, Kinesis Data Streams, Kinesis Data Firehose
- Orchestration: Step Functions, CodePipeline, CodeBuild
- Maintenance: SSM, EC2 Actions
CloudWatch Container Insight
- Collect, aggregate, summarize metrics and logs from containers
- Available for containers on...
- Amazon Elastic Container Service (Amazon ECS)
- Amazon Elastic Kubernetes Services (Amazon EKS)
- Kubernetes platforms on EC2
- Fargate (both for ECS and EKS)
- In Amazon EKS and Kubernetes, CloudWatch Insights is using a containerized version of the CloudWatch Agent to discover containers
CloudWatch Lambda Insights
- Monitoring and troubleshooting solution for serverless applications running on AWS Lambda
- Collects, aggregates, and summarizes system-level metrics including CPU time, memory, disk, and network
- Collects, aggregates, and summarizes diagnostic information such as cold starts and Lambda worker shutdowns
- Lambda Insights is provided as a Lambda Layer
CloudWatch Contributor Insights
- Analyze log data and create time series that display contributor data.
- See metrics about the top-N contributors
- The total number of unique contributors, and their usage.
- This helps you find top talkers and understand who or what is impacting system performance.
- Works for any AWS-generated logs (VPC, DNS, etc..)
- For example, you can find bad hosts, identify the heaviest network users, or find the URLs that generate the most errors.
- You can build your rules from scratch, or you can also use sample rules that AWS has created – leverages your CloudWatch Logs
- CloudWatch also provides built-in rules that you can use to analyze metrics from other AWS services.
CloudWatch Application Insights
- Provides automated dashboards that show potential problems with monitored applications, to help isolate ongoing issues
- Your applications run on Amazon EC2 Instances with select technologies only (Java, .NET, Microsoft IIS Web Server, databases...)
- And you can use other AWS resources such as Amazon EBS, RDS, ELB, ASG, Lambda, SQS, DynamoDB, S3 bucket, ECS, EKS, SNS, API Gateway...
- Powered by SageMaker
- Enhanced visibility into your application health to reduce the time it will take you to troubleshoot and repair your applications
- Findings and alerts are sent to Amazon EventBridge and SSM OpsCenter
CloudWatch Synthetics
Amazon CloudWatch Synthetics allows you to create canaries that simulate customer behavior and monitor the availability
- You can use Amazon CloudWatch Synthetics to create canaries, configurable scripts that run on a schedule, to monitor your endpoints and APIs.
- Canaries follow the same routes and perform the same actions as a customer, which makes it possible for you to continually verify your customer experience even when you don't have any customer traffic on your applications.
- By using canaries, you can discover issues before your customers do.
Amazon EventBridge
EventBridge used to be known as CloudWatch Events
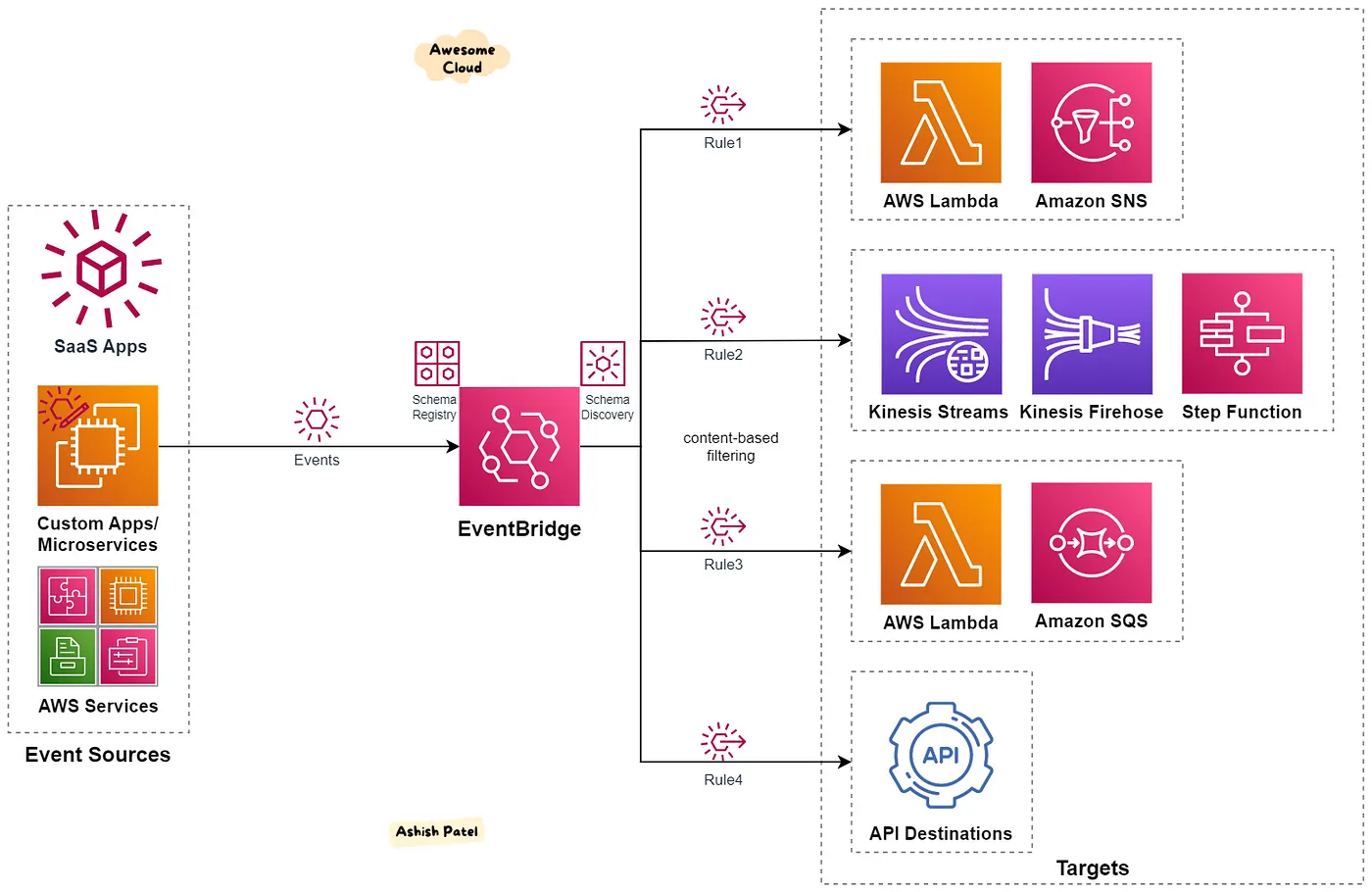
Default event bus: generated by AWS services (CloudWatch Events)Partner event bus: receive events from SaaS service or applications (Zendesk, DataDog, Segment, Auth0...)Custom Event buses: for your own applications- Schema Registry: model event schema
- EventBridge has a different name to mark the new capabilities
- The CloudWatch Events name will be replaced with EventBridge
AWS CloudTrail
- Provides governance, compliance and audit for your AWS Account
- CloudTrail is enabled by default
- Get an history of events / API calls made within your AWS Account by:
- Console
- SDK
- CLI
- AWS Services
- Can put logs from CloudTrail into CloudWatch Logs or S3
- A trail can be applied to All Regions (default) or a single Region.
- If a resource is deleted in AWS, investigate CloudTrail first!
- By default, management events are logged and retained for 90 days
- A CloudTrail Trail logs any events to S3 for indefinite retention
- Trail can be within Region or all Regions
Tip
CloudTrail logs record information about:
- Who requested the action?
- Where did the request originate from and when?
- What was requested?
- The full API response
Tip
CloudTrail Trails can be configured as multi-region trails which will log events from all regions. These logs can be delivered to a single Amazon S3 bucket. CloudTrail should have write permission on this Amazon S3 bucket to deliver logs.
CloudTrail Events
- Provide information about management operations that are performed on resources in your AWS account
- Examples:
- Configuring security (IAM AttachRolePolicy)
- Configuring rules for routing data (Amazon EC2 CreateSubnet)
- Setting up logging (AWS CloudTrail CreateTrail)
- By default, trails are configured to log management events.
- Can separate Read Events (that don’t modify resources) from Write Events (that may modify resources)
- Provide information about the resource operations performed on or in a resource
- By default, data events are not logged (because high volume operations)
- Amazon S3 object-level activity (ex: GetObject, DeleteObject, PutObject): can separate Read and Write Events
- AWS Lambda function execution activity (the Invoke API)
- Identify and respond to unusual activity associated with write API calls by continuously analyzing CloudTrail management events
- These events are generated only when there are significant variations from normal usage patterns.
Note
- CloudWatch Events can triggered based on API calls in CloudTrail
- Events can be streamed to CloudWatch Logs
Example
- data events:
- Amazon S3 object-level API activity (for example, GetObject, DeleteObject, and PutObject API operations)
- AWS Lambda function invocation activity (for example, InvokeFunction API operations)
- Amazon DynamoDB object-level API activity on tables (for example, PutItem, DeleteItem, and UpdateItem)
- management events:
- Creating an Amazon S3 bucket
- Creating and managing AWS IAM resources
- Registering devices
- Configuring routing table rules
CloudTrail Insights
- Enable CloudTrail Insights to detect unusual activity in your account:
- inaccurate resource provisioning
- hitting service limits
- Bursts of AWS IAM actions
- Gaps in periodic maintenance activity
- CloudTrail Insights analyzes normal management events to create a baseline
- And then continuously analyzes write events to detect unusual patterns
- Anomalies appear in the CloudTrail console
- Event is sent to Amazon S3
- An EventBridge event is generated (for automation needs)
CloudTrail Events Retention
- Events are stored for 90 days in CloudTrail
- To keep events beyond this period, log them to S3 and use Athena
Validate CloudTrail Log File Integrity
- To determine whether a log file was modified, deleted, or unchanged after CloudTrail delivered it, you can use CloudTrail log file integrity validation.
- When you enable log file integrity validation, CloudTrail creates a hash for every log file that it delivers.
- Every hour, CloudTrail also creates and delivers a file that references the log files for the last hour and contains a hash of each. This file is called a digest file. Validated log files are invaluable in security and forensic investigations
Tip
Digest file is delivered in the same Amazon S3 bucket but in a separate folder as that of CloudTrail Log files. Separate security policies can be implemented on a folder consisting of digest files.
AWS X-Ray
advantages
- Troubleshooting performance (bottlenecks)
- Understand dependencies in a microservice architecture
- Pinpoint service issues
- Review request behavior
- Find errors and exceptions
- Are we meeting time SLA?
- Where I am throttled?
- Identify users that are impacted
compatibility
- AWS Lambda
- Elastic Beanstalk
- ECS
- ELB
- API Gateway
- EC2 Instances or any application server (even on premise)
- SQS
Concepts
- Segments:
- consists of tracing records for a request which a distributed application makes
- consists of multiple system defined & user-defined annotations
- Subsegments: consist of remote calls made from application
- Trace: segments collected together to form an end-to-end trace
- Sampling: decrease the amount of requests sent to X-Ray, reduce cost
- Annotations: Key Value pairs used to index traces and use with filters, consist of system-defined & user-defined data
- Metadata: Key Value pairs, not indexed, not used for searching
Service Maps
- AWS X-Ray Service maps can be used to create dependency trees between services across multiple AWS regions
- They also detect latency between these services which can help resolve performance issues
CloudTrail vs CloudWatch vs X-Ray
- Audit API calls made by users / services / AWS console
- Useful to detect unauthorized calls or root cause of changes
- CloudWatch Metrics over time for monitoring
- CloudWatch Logs for storing application log
- CloudWatch Alarms to send notifications in case of unexpected metrics
- Automated Trace Analysis & Central Service Map Visualization
- Latency, Errors and Fault analysis
- Request tracking across distributed systems
ServiceLens
ServiceLens can be used to enhance application health monitoring by integrating traces, metrics, logs, alarms, and other resource health information into one place.
ServiceLens integrates with X-Ray to provide an end-to-end view of the application.
ServiceLens can be deployed with the following 2 steps:
- Deploy X-Ray
- Deploy the CloudWatch agent and the X-Ray daemon
AWS Status - Service Health Dashboard
- Shows all regions, all services current status information on service availability
- Shows historical information for each day
- Has an RSS feed you can subscribe to
Note
Not personalized information so may not be relevant to you No proactive notification of scheduled activities
AWS Personal Health Dashboard
- AWS Personal Health Dashboard provides alerts and remediation guidance when AWS is experiencing events that may impact you.
- While the Service Health Dashboard displays the general status of AWS services, Personal Health Dashboard gives you a personalized view into the performance and availability of the AWS services underlying your AWS resources.
- Also provides proactive notification to help you plan for scheduled activities
- The dashboard displays relevant and timely information to help you manage events in progress and provides proactive notification to help you plan for scheduled activities.
Amazon Managed Service for Prometheus
Prometheus is an open-source monitoring system and time series database
- Use the open-source Prometheus query language (PromQL) to monitor and alert on the performance of containerized workloads
- Automatically scales the ingestion, storage, alerting, and querying of operational metrics as workloads grow or shrink
- Integrated with Amazon EKS, Amazon ECS, and AWS Distro for OpenTelemetry
Amazon Managed Grafana
Grafana is an open-source analytics and monitoring solution for databases
- Highly scalable, highly available, and fully managed service Grafana
- Provides interactive data visualization for your monitoring and operational data
- Visualize, analyze, and alarm on your metrics, logs, and traces collected from multiple data sources
- Integrates with AWS SSO and SAML
Security & Compliance
AWS Shared Responsibility Model
- AWS responsibility - Security of the Cloud
- Protecting infrastructure (hardware, software, facilities, and networking) that runs all the AWS services
- Managed services like S3, DynamoDB, RDS, etc.
- Customer responsibility - Security in the Cloud
- For EC2 instance, customer is responsible for management of the guest OS (including security patches and updates), firewall & network configuration, IAM
- Encrypting application data
- Shared controls:
- Patch Management, Configuration Management, Awareness & Training
DDOS Protection on AWS
- AWS Shield Standard: protects against DDOS attack for your website and applications, for all customers at no additional costs
- AWS Shield Advanced: 24/7 premium DDoS protection
- AWS WAF: Filter specific requests based on rules
- CloudFront and Route 53:
- Availability protection using global edge network
- Combined with AWS Shield, provides attack mitigation at the edge
AWS WAF – Web Application Firewall

- Protects your web applications from common web exploits (Layer 7)
- Deploy on:
- Application Load Balancer
- API Gateway REST API
- CloudFront
- AppSync
Concepts
Web ACLs– You use a web access control list (ACL) to protect a set of AWS resourcesRules– Each rule contains a statement that defines the inspection criteria, and an action to take if a web request meets the criteria. Can be created based on conditions like HTTP headers, HTTP body, URI strings, SQL injection, and cross-site scriptingRule groups– You can use rules individually or in reusable rule groupsIP Sets- An IP set provides a collection of IP addresses and IP address ranges that you want to use together in a rule statementRegex Pattern Set- A regex pattern set provides a collection of regular expressions that you want to use together in a rule statement
Tip
You are charged for each web ACL configured on AWS WAF.
Define Web ACL (Web Access Control List)
- Rules can include IP addresses, HTTP headers, HTTP body, or URI strings
- Protects from common attack - SQL injection and Cross-Site Scripting (XSS)
- Size constraints, geo-match (block countries)
- Rate-based rules (to count occurrences of events) – for DDoS protection
Tip
- A web ACL can allow or deny traffic based on the source IP address, country of origin of the request, string match or regular expression (regex) match, or the detection of malicious SQL code or scripting.
- You can also use the logs that are generated to examine the number of requests, the nature of those requests, and where they originate from.
Rule Action
A rule action tells AWS WAF what to do with a web request when it matches the criteria defined in the rule
- Count – AWS WAF counts the request but doesn't determine whether to allow it or block it. With this action, AWS WAF continues processing the remaining rules in the web ACL
- Allow – AWS WAF allows the request to be forwarded to the AWS resource for processing and response
- Block – AWS WAF blocks the request and the AWS resource responds with an HTTP 403 (Forbidden) status code
Match Statement
Match statements compare the web request or its origin against conditions that you provide
| Match Statement | Description |
|---|---|
| Geographic match | Inspects the request's country of origin |
| IP set match | Inspects the request against a set of IP addresses or address ranges |
| Regex pattern set match | Inspects the request against a set of regular expressions |
| Size constraint | Inspects the request for length, width, or depth |
| SQL injection match | Inspects the request for SQL code that is intended to execute malicious commands |
| String match | Compares a string to a specified request component, such as the URI or query string |
| XSS match | Inspects the request for cross-site scripting attacks |
AWS Shield
- AWS Shield is a managed Distributed Denial of Service (DDoS) protection service
- Safeguards web application running on AWS with always-on detection and automatic inline mitigations
- Helps to minimize application downtime and latency
- Two tiers
- Standard
- Automatically enabled free of charge for all AWS customers
- Defends against frequently occurring network and transport layer DDoS attacks
- Incoming traffic is inspected for malicious patterns in real time
- Advanced
- Provides mitigations against large and sophisticated DDoS attacks and near real-time visibility into attacks
- AWS Shield Advanced also provides integration with AWS Web Application Firewall
- Protects resources on EC2, Elastic Load Balancing, CloudFront, AWS Global Accelerator, and Route 53
- Standard
- Integrated with Amazon CloudFront (standard included by default)
Why encryption?
- Data is encrypted before sending and decrypted after receiving
- SSL certificates help with encryption (HTTPS)
- Encryption in flight ensures no MITM (man in the middle attack) can happen
- Data is encrypted after being received by the server
- Data is decrypted before being sent
- It is stored in an encrypted form thanks to a key (usually a data key)
- The encryption / decryption keys must be managed somewhere and the server must have access to it
- Data is encrypted by the client and never decrypted by the server
- Data will be decrypted by a receiving client
- The server should not be able to decrypt the data
- Could leverage Envelope Encryption
AWS KMS (Key Management Service)
KMS = AWS manages the encryption keys for us
- Fully integrated with IAM for authorization
- Create and managed
symmetricandasymmetricencryption keys - The KMS keys are protected by hardware security modules (HSMs)
- Easy way to control access to your data
- Able to audit KMS Key usage using CloudTrail
- Seamlessly integrated into most AWS services (EBS, S3, RDS, SSM…)
Danger
Never ever store your secrets in plaintext, especially in your code!
KMS Key Encryption also available through API calls (SDK, CLI) Encrypted secrets can be stored in the code / environment variables
- Encryption Opt-in:
- EBS volumes: encrypt volumes
- S3 buckets: Server-side encryption of objects
- Redshift database: encryption of data
- RDS database: encryption of data
- EFS drives: encryption of data
- Encryption Automatically enabled:
- CloudTrail Logs
- S3 Glacier
- Storage Gateway
KMS Key Types
KMS Keys is the new name of KMS Customer Master Key
- Single encryption key that is used to Encrypt and Decrypt
- AWS services that are integrated with KMS use Symmetric CMKs
- You never get access to the KMS Key unencrypted (must call KMS API to use)
- Public (Encrypt) and Private Key (Decrypt) pair
- Used for Encrypt/Decrypt, or Sign/Verify operations
- The public key is downloadable, but you can’t access the Private Key unencrypted
- Use case: encryption outside of AWS by users who can’t call the KMS API
Key Types
- Three types of KMS Keys:
- AWS Managed Keys: free (aws/service-name, example: aws/rds or aws/ebs)
- Customer Managed Keys (CMK) created in KMS: $1 / month
- Customer Managed Keys imported (must be 256-bit symmetric key): $1 / month
- + pay for API call to KMS ($0.03 / 10000 calls)
Tip
If you choose to import keys to AWS KMS or asymmetric keys or use a custom key store, you can manually rotate them by creating a new KMS key and mapping an existing key alias from the old KMS key to the new KMS key.
Info
AWS Managed KMS Keys
- Created, managed, and used on your behalf by an AWS service that is integrated with AWS KMS
- You cannot manage these KMS keys, rotate them, or change their key policies
- You also cannot use AWS managed KMS keys in cryptographic operations directly; the service that creates them uses them on your behalf
Automatic Key Rotation
- AWS-managed KMS Key: automatic every 1 year
- Customer-managed KMS Key: (must be enabled) automatic every 1 year
- Imported KMS Key: only manual rotation possible using alias
Note
Rotation only changes the key material used for encryption, the KMS key remains the same
With automatic key rotation:
- The properties of the KMS key, including its key ID, key ARN, region, policies, and permissions, do not change when the key is rotated
- You do not need to change applications or aliases that refer to the key ID or key ARN of the KMS key
- After you enable key rotation, AWS KMS rotates the KMS key automatically every year
Automatic key rotation is not supported on the following types of KMS keys:
- Asymmetric KMS keys
- HMAC KMS keys
- KMS keys in custom key stores
- KMS keys with imported key material
Info
You can rotate these KMS keys manually
Manual Rotation
- Manual rotation is creating a new KMS key with a different key ID
- You must then update your applications with the new key ID
- You can use an alias to represent a KMS key so you don’t need to modify your application code
Alternative Key Stores
External Key Store
- Keys can be stored outside of AWS to meet regulatory requirements
- You can create a KMS key in an AWS KMS external key store (XKS)
- All keys are generated and stored in an external key manager
- When using an XKS, key material never leaves your HSM
Custom Key Store
- You can create KMS keys in an AWS CloudHSM custom key store
- All keys are generated and stored in an AWS CloudHSM cluster that you own and manage
- Cryptographic operations are performed solely in the AWS CloudHSM cluster you own and manage
- Custom key stores are not available for asymmetric KMS keys
KMS Key Policies
- Key policies define management and usage permissions for KMS keys( "similar" to S3 bucket policies)
- Difference: you cannot control access without them
- Multiple policy statements can be combined to specify separate administrative and usage permissions
- Permissions can be specified for delegating use of the key to AWS services
- Default KMS Key Policy:
- Created if you don’t provide a specific KMS Key Policy
- Complete access to the key to the root user = entire AWS account
- Custom KMS Key Policy:
- Define users, roles that can access the KMS key
- Define who can administer the key
- Useful for cross-account access of your KMS key
Tip
- To share snapshots with another account you must specify
DecryptandCreateGrantpermissions - The
kms:ViaServicecondition key can be used to limit key usage to specific AWS services - Cryptographic erasure means removing the ability to decrypt data and can be achieved when using
imported key materialand deleting that key material - You must use the
DeletelmportedKeyMaterialAPI to remove the key material - An
InvalidKeyIdexception when using SSM Parameter Store indicates the KMS key is not enabled
Envelope Encryption
- KMS Encrypt API call has a limit of 4 KB
- If you want to encrypt >4 KB, we need to use Envelope Encryption
- The main API that will help us is the
GenerateDataKeyAPI
API & CLI
Encrypt (aws kms encrypt):
- Encrypts plaintext into ciphertext by using a KMS key
- You can encrypt small amounts of arbitrary data, such as a personal identifier or database password, or other sensitive information
- You can use the Encrypt operation to move encrypted data from one AWS region to another
Decrypt (aws kms decrypt):
- Decrypts ciphertext that was encrypted by an KMS key using any of the following operations:
- Encrypt
- GenerateDataKey
- GenerateDataKeyPair
- GenerateDataKeyWithoutPlaintext
- GenerateDataKeyPairWithoutPlaintext
Re-encrypt (aws kms re-encrypt):
- Decrypts ciphertext and then re-encrypts it entirely within AWS KMS
- You can use this operation to change the KMS key under which data is encrypted, such as when you manually rotate a KMS key or change the KMS key that protects a ciphertext
- You can also use it to re-encrypt ciphertext under the same KMS key, such as to change the encryption context of a ciphertext
Enable-key-rotation:
- Enables automatic rotation of the key material for the specified symmetric KMS key
- You cannot perform this operation on a KMS key in a different AWS account
GenerateDataKey (aws kms generate-data-key):
- Generates a unique symmetric data key
- This operation returns a plaintext copy of the data key and a copy that is encrypted under a KMS key that you specify
- You can use the plaintext key to encrypt your data outside of AWS KMS and store the encrypted data key with the encrypted data
GenerateDataKeyWithoutPlaintext (generate-data-key-without-plaintext):
- Generates a unique symmetric data key
- This operation returns a data key that is encrypted under a KMS key that you specify
- To request an asymmetric data key pair, use the GenerateDataKeyPair or GenerateDataKeyPairWithoutPlaintext operations
Throttling and Caching
- AWS KMS has two types of quotas:
- Resourcequotas
- Request quotas
- If you exceed a resource limit, requests to create an additional resource of that type generate an LimitExceededException error message
- Request quotas apply to API actions such as Encrypt, Decrypt, ReEncrypt, and GenerateDataKey
- To prevent throttling, you can:
- Implement a backoff and retry strategy
- Request a service quota increase
- Implement data key caching
- Data key caching stores data keys and related cryptographic material in a cache
- Useful if your application:
- Can reuse data keys
- Generates numerous data keys
- Runs cryptographic operations that are unacceptably slow, expensive, limited, or resource-intensive
- You can create a local cache using the AWS Encryption SDK and the
LocalCryptoMaterialsCachefeature
Encryption SDK
- The AWS Encryption SDK implemented Envelope Encryption for us
- The Encryption SDK also exists as a CLI tool we can install
- Implementations for Java, Python, C, JavaScript
- Feature - Data Key Caching:
- re-use data keys instead of creating new ones for each encryption
- Helps with reducing the number of calls to KMS with a security trade-off
- Use LocalCryptoMaterialsCache (max age, max bytes, max number of messages)
CloudHSM
KMS => AWS manages the software for encryption
CloudHSM => AWS provisions encryption hardware
- Dedicated Hardware (HSM = Hardware Security Module)
- You manage your own encryption keys entirely (not AWS)
- HSM device is tamper resistant, FIPS 140-2 Level 3 compliance
- CloudHSM runs in your Amazon VPC
- Uses FIPS 140-2 level 3 validated HSMs
- Managed service and automatically scales
- Retain control of your encryption keys - you control access (and AWS has no visibility of your encryption keys)
- Use Cases:
- Offload SSL/TLS processing from web servers
- Protect private keys for an issuing certificate authority (CA)
- Store the master key for Oracle DB Transparent Data Encryption
- Custom key store for AWS KMS – retain control of the HSM that protects the master keys
AWS Certificate Manager (ACM)
- Easily provision, manage, and deploy SSL/TLS X.509 Certificates
- Used to provide in-flight encryption for websites (HTTPS)
- Supports both public and privateTLS certificates
- Free of charge for publicTLS certificates
- AutomaticTLS certificate renewal
- Single domains, multiple domain names and wildcards
- Integrates with several AWS services including:
- Elastic Load Balancers
- Amazon CloudFront Distributions
- AWS API Gateway
- AWS Elastic Beanstalk
- AWS Nitro Enclaves
- AWS CloudFormation
- AWS App Runner
- Public certificates are signed by the AWS public Certificate Authority
- You can also create a Private CA with ACM
- Can then issue private certificates
- You can also import certificates from third-party issuers
SSM Parameter Store
- Parameter Store provides secure, hierarchical storage for configuration data and secrets
- Optional Seamless Encryption using KMS
- Serverless, scalable, durable, easy SDK
- Version tracking of configurations / secrets
- Security through IAM
- Notifications with Amazon EventBridge
- Integration with CloudFormation
- Store data such as passwords, database strings, and license codes as parameter values
- Store values as plaintext (unencrypted data) or ciphertext (encrypted data)
- Reference values by using the unique name that you specified when you created the parameter
- No native rotation of keys (difference with AWS Secrets Manager which does it automatically)
AWS Secrets Manager
- Stores and rotate secrets safely without the need for code deployments
- Capability to force rotation of secrets every X days
- Automate generation of secrets on rotation (uses Lambda)
- Built-in Integration with:
- Amazon RDS (MySQL, PostgreSQL, Aurora)
- Amazon Redshift
- Amazon DocumentDB
- Secrets are encrypted using KMS
Tip
AWS Secrets Manager can be configured to replicate secrets across multiple regions. With this feature, multi-region applications like Amazon RDS can retrieve secrets locally within the region instead of retrieving secrets across the regions.
Following are features when AWS Secrets Manager is configured to replicate secrets in multiple regions:
- Replicated Secrets will have a common name across all regions.
- Secrets Manager replicates all encrypted secrets and metadata.
SSM Parameter Store vs Secrets Manager
- Automatic rotation of secrets with AWS Lambda
- Lambda function is provided for RDS, Redshift, DocumentDB
- KMS encryption is mandatory
- Can integrate with CloudFormation
- Simple API
- No secret rotation (can enable rotation using Lambda triggered by CW Events)
- KMS encryption is optional
- Can integration with CloudFormation
- Can pull a Secrets Manager secret using the SSM Parameter Store API
Amazon Inspector
- Runs assessments that check for security exposures and vulnerabilities in EC2 instances
- For EC2 instances
- Leveraging the AWS System Manager (SSM) agent
- Analyze against unintended network accessibility
- Analyze the running OS against known vulnerabilities
- For Containers push to Amazon ECR
- Assessment of containers as they are pushed
- Reporting & integration with
AWS Security Hub - Send findings to
Amazon Event Bridge - Only evaluate for EC2 instances and container infrastructure
- Can be configured to run on a schedule
- Agent must be installed on EC2 for host assessments
- Network assessments do not require an agent
Tip
An assessment template for Amazon Inspector consists of the following parameters:
- Name
- Target Name
- Rules Package
- Duration
Optional Parameters are:
- SNS Topics
- Tag
- Attributes added to findings
- Assessment Schedule
Network Assessments
- Assessments: Network configuration analysis to check for ports reachable from outside the VPC
- If the Inspector Agent is installed on your EC2 instances, the assessment also finds processes reachable on port
- Price based on the number of instance assessments
Host Assessments
- Assessments: Vulnerable software (CVE), host hardening (CISbenchmarks), and security best practices
- Requires an agent (auto-install with SSM Run Command)
- Price based on the number of instance assessments
AWS GuardDuty
- Intelligent threat detection service
- Not turned on by default
- Detects account compromise, instance compromise, malicious reconnaissance, and bucket compromise
- Continuous monitoring for events across:
AWS CloudTrail Management EventsAWS CloudTrail S3 Data EventsAmazon VPC Flow LogsDNS Logs
- For an automated preventive action based upon Amazon GuardDuty findings,
Amazon CloudWatch EventsandAmazon Lambdafunction can be used. - Amazon GuardDuty findings are sent to Amazon CloudWatch events based upon match criteria, triggers an AWS Lambda function which will modify VPC NACLs based upon Amazon GuardDuty findings.
Note
Key features:
- Account-level threat detection to determine whether AWS accounts may have been compromised
- The ability to create automated threat response actions
- Monitoring of potential reconnaissance attempts
- Monitoring of possible EC2 instance compromises
- Monitoring of possible S3 bucket compromises
Tip
Amazon GuardDuty creates an event for Amazon CloudWatch Events when any change in findings occurs. For each of the findings, a finding ID is assigned. For newly generated findings with unique finding ID, notifications are sent within 5 minutes of the findings. But all subsequent findings are aggregated to a single event, and notifications are sent every 6 hours.
AWS Config
- Evaluate your AWS resource configurations for desired settings
- Get a snapshot of the current configurations of resources that are associated with your AWS account
- Retrieve configurations of resources that exist in your account
- Retrieve historical configurations of one or more resources
- Receive a notification whenever a resource is created, modified, or deleted
- View relationships between resources
- Possibility of storing the configuration data into S3 (analyzed by Athena)
Tip
- Questions that can be solved by AWS Config:
- Is there unrestricted SSH access to my security groups?
- Do my buckets have any public access?
- How has my ALB configuration changed over time?
- You can receive alerts (SNS notifications) for any changes(whenever a resource is created, modified, or deleted)
- AWS Config is a per-region service
- Can be aggregated across regions and accounts
- AWS Config Dashboard provides an overview of resources, config rules and compliance status of both resources and rules. The dashboard displays details of the resources and rules only specific to a region and an account.
Example
Example Rules:
cloudtrail-enabled: Checks whether CloudTrail is enabled in your AWS accounts3-bucket-versioning-enabled: Checks whether versioning is enabled for your S3 bucketsrestricted-ssh: Checks whether security groups allow unrestricted SSH accessrds-instance-public-access-check: Checks whether RDS instances are publicly accessiblecloudtrail-enabled: Checks whether CloudTrail is enabled in your AWS account, If CloudTrail is turned off, this rule automatically re-enables it by using automatic remediation.approved-amis-by-id: Checks whether the AMIs used by your EC2 instances are approved
Aggregators
- To aggregate compliance data from multiple accounts & multiple regions into a single account, Multi-Account Multi-Region Data Aggregation can be used.
- For this, an Aggregator needs to be created in a region where aggregated AWS Config configuration and compliance data are required.
- Aggregator collects compliance data from multiple source accounts and from multiple regions. Source Accounts that are part of AWS Organizations do not require to provide any authorization.
- Source accounts that are not part of AWS Organizations require authorization which permits Aggregator to collect AWS Config configuration and compliance data.
- An aggregator dashboard can be used to view the total number of resources and the non-compliance resources for multiple accounts and regions
AWS Resource Access Manager (RAM)
- Shares resources:
- Across AWS accounts
- Within AWS Organizations or OUs
- IAM roles and IAM users
- Resource shares are created with:
- The AWS RAM Console
- AWS RAM APIs
- AWS CLI
- AWS SDKs
- RAM can be used to share with:
- AWS App Mesh
- Amazon Aurora
- AWS Certificate Manager Private Certificate Authority
- AWS CodeBuild
- Amazon EC2
- EC2 Image Builder
- AWS Glue
- AWS License Manager
- AWS Network Firewall
- AWS Outposts
- Amazon S3 on Outposts
- AWS Resource Groups
- Amazon Route 53
- AWS Systems Manager Incident Manager
- Amazon VPC
Amazon Macie
Macie is a fully managed data security and data privacy service
- Uses machine learning and pattern matching to discover, monitor, and help you protect your sensitive data on Amazon S3 by creating and running sensitive data discovery jobs
- Macie enables security compliance and preventive security as follows:
- Identify a variety of data types, including PII, Protected Health Information (PHI), regulatory documents, API keys, and secret keys
- Identify changes to policy and access control lists
- Continuously monitor the security posture of Amazon S3
- Generate security findings that you can view using the Macie console, AWS Security Hub, or Amazon EventBridge
- Manage multiple AWS accounts using AWS Organizations
Amazon Detective
Amazon Detective analyzes, investigates, and quickly identifies the root cause of security issues or suspicious activities (using ML and graphs)
- Automatically collects and processes events from VPC Flow Logs, CloudTrail, GuardDuty and create a unified view
- Produces visualizations with details and context to get to the root cause
AWS Abuse
- Report suspected AWS resources used for abusive or illegal purposes
- Abusive & prohibited behaviors are:
- Spam – receving undesired emails from AWS-owned IP address, websites & forums spammed by AWS resources
- Port scanning – sending packets to your ports to discover the unsecured ones
- DoS or DDoS attacks – AWS-owned IP addresses attempting to overwhlem or crash your servers/softwares
- Intrusion attempts – logging in on your resources
- Hosting objectionable or copyrighted content – distributing illegal or copyrighted content without consent
- Distributing malware – AWS resources distributing softwares to harm computers or machines
Root user privileges
Root user = Account Owner (created when the account is created)
- Has complete access to all AWS services and resources
- Lock away your AWS account root user access keys!
- Do not use the root account for everyday tasks, even administrative tasks
- Actions that can be performed only by the root user:
- Change account settings(account name, email address, rootuser password, rootuser accesskeys)
- View certain tax invoices
- Close your AWS account
- Restore IAM user permissions
- Change or cancel your AWS Support plan
- Register as a seller in the Reserved Instance Marketplace
- Configure an Amazon S3 bucket to enable MFA
- Editor delete an Amazon S3 bucket policy that includes an invalid VPC ID or VPC endpoint ID
- Sign up for GovCloud
AWS Directory Services
AWS Managed Microsoft AD
- Fully managed AWS service
- Best choice if you have more than 5000 users and/or need a trust relationship set up
- Can perform schema extensions
- Can setup trust relationships to with on-premises Active Directories:
- On-premise users and groups can access resources in either domain using SSO
- Requires a VPN or Direct Connect connection
- Can be used as a standalone AD in the AWS cloud
AD Connector
- Redirects directory requests to your on-premise Active Directory
- Best choice when you want to use an existing Active Directory with AWS services
- AD Connector comes in two sizes:
- Small – designed for organizations up to 500 users
- Large – designed for organizations up to 5000 users
- Requires a VPN or Direct Connect connection
- Join EC2 instances to your on-premise AD through AD Connector
- Login to the AWS Management Console using your on-premise AD DCs for authentication
Simple AD
- Inexpensive Active Directory-compatible service with common directory features
- Standalone, fully managed, directory on the AWS cloud
- Simple AD is generally the least expensive option
- Best choice for less than 5000 users and don’t need advanced AD features
- Features include:
- Manage user accounts / groups
- Apply group policies
- Kerberos-based SSO
- Supports joining Linux or Windows based EC2 instances
AWS License Manager
- Used to manage licenses from software vendors
- For example, manage your Microsoft, Oracle, SAP and IBM licenses
- Centralized management of software licenses for AWS and on-premises resources
- Can track license usage including when licensed based on virtual cores (vCPUs), sockets, or number of machines
- Distribute, activate, and track software licenses across accounts and throughout an organization
- Enforce limits across multiple Regions
AWS Trusted Advisor
AWS Trusted Advisor is a tool that performs checks on five different categories:
- Cost optimization
- Performance
- Security
- Fault tolerance
- Service limits
Trusted Advisor provides real time guidance to help you provision your resources following best practices
Tip
- The quantity of available Trusted Advisor checks is affected by the
AWS Support plan. - The AWS Support plan determines which Trusted Advisor checks are available for an account.
- Basic Support provides access to 7 core Trusted Advisor checks, Developer Support provides access to 29 core Trusted Advisor checks, while Business and Enterprise Support provide access to all Trusted Advisor checks and guidance.
AWS Security Hub
The AWS Security Hub allows you to execute security checks across your AWS environment automatically.
- Provides cloud security posture management
- Run security best practice configuration checks such as
- AWS Foundational Security Best Practices
- Center for Internet Security (CIS)
- Payment Card Industry (PCI DSS)
- Aggregates alerts and provides automated remediation
- Integrations include:
Amazon EventBridge– send alerts and trigger targetsSystems Manager– automation via runbooksAWS Organizations– consolidated findings across accounts- Ticketing, chat, incident management, investigation, GRC, SOAR, and SIEM tools
It also allows you to gather alerts from the following security policies into a central view:
- Amazon GuardDuty
- Amazon Inspector
- IAM Access Analyzer
- Amazon Macie
- IAM Firewall Manager
- Amazon System Manager
AWS Systems Manager
AWS Systems Manager is a secure end-to-end management solution for resources on AWS, on premises, and on other clouds
- Systems Manager is an operations hub for
operations management,application management,change managementandnode management - You can manage Amazon EC2 instances and on-premises servers and virtual machines (VMs), including VMs hosted by other cloud providers
- The SSM Agent must be installed on managed instances and servers
- IAM permissions must be configured to allow management
- For hybrid environments an IAM service role is used with hybrid activation
- Systems Manager components include:
- Automation
- Run Command
- Inventory
- Patch Manager
- Compliance
- Session Manager
- Parameter Store
Note
By default, AWS Systems Manager doesn't have permission to perform actions on your instances. Grant access by using an AWS Identity and Access Management (IAM) instance profile. An instance profile is a container that passes IAM role information to an Amazon Elastic Compute Cloud (Amazon EC2) instance at launch. You can create an instance profile for Systems Manager by attaching one or more IAM policies that define the necessary permissions to a new role or to a role you already created.
Systems Manager Patch Manager
- Helps you select and deploy operating system and software patches automatically across large groups of Amazon EC2 or on-premises instances
- Patch baselines:
- Set rules to auto-approve select categories of patches to be installed
- Specify a list of patches that override these rules and are automatically approved or rejected
- You can also schedule maintenance windows for your patches so that they are only applied during predefined times
- Systems Manager helps ensure that your software is up-to-date and meets your compliance policies
Systems Manager Compliance
- AWS Systems Manager lets you scan your managed instances for patch compliance and configuration inconsistencies
- You can collect and aggregate data from multiple AWS accounts and Regions, and then drill down into specific resources that aren’t compliant
- By default, AWS Systems Manager displays data about patching and associations
- You can also customize the service and create your own compliance types based on your requirements (must use the AWS CLI, AWS Tools for Windows PowerShell, or the SDKs)
Systems Manager Session Manager
- Secure remote management of your instances at scale without logging into your servers
- Replaces the need for bastion hosts, SSH, or remote PowerShell
- Integrates with IAM for granular permissions
- All actions taken with Systems Manager are recorded by AWS CloudTrail
- Can store session logs in an S3 bucket and output to CloudWatch Logs
- Requires IAM permissions for EC2 instance to access SSM, S3, and CloudWatch Logs
Tip
Doesn't require open ports: 22, 5985, 5986
No need for bastion hosts
Systems Manager Parameter Store
- Parameter Store provides secure, hierarchical storage for configuration data management and secrets management
- Highly scalable, available, and durable
- Store data such as passwords, database strings, and license codes as parameter values
- Store values as plaintext (unencrypted data) or ciphertext (encrypted data)
- Reference values by using the unique name that you specified when you created the parameter
- No native rotation of keys (difference with AWS Secrets Manager which does it automatically)
Machine Learning
Amazon Rekognition
- Find objects, people, text, scenes in images and videos using ML
- Facial analysis and facial search to do user verification, people counting
- Create a database of "familiar faces" or compare against celebrities
- Processes videos stored in an Amazon S3 bucket
- Publish completion status to Amazon SNS Topic
- Use cases:
- Labeling
- Content Moderation
- Text Detection
- Face Detection and Analysis (gender, age range, emotions...)
- Face Search and Verification
- Celebrity Recognition
- Pathing
Amazon Transcribe
- Automatically convert speech to text
- Uses a deep learning process called automatic speech recognition (ASR) to convert speech to text quickly and accurately
- Automatically remove Personally Identifiable Information (PII) using Redaction
- Supports Automatic Language Identification for multi-lingual audio
- Use cases:
- transcribe customer service calls
- automate closed captioning and subtitling
- generate metadata for media assets to create a fully searchable archive
Amazon Polly
- Turns text into lifelike speech
- Create applications that talk, and build entirely new categories of speech-enabled products
- Text-to-Speech (TTS) service uses advanced deep learning technologies to synthesize natural sounding human speech
Amazon Translate
- Neural machine translation service that delivers fast, high-quality, and affordable language translation
- Uses deep learning models to deliver more accurate and more natural sounding translation
- Localize content such as websites and applications for your diverse users
Amazon Lex & Connect
- Amazon Lex: (same technology that powers Alexa)
- Automatic Speech Recognition (ASR) to convert speech to text
- Natural Language Understanding to recognize the intent of text, callers
- Helps build chatbots, call center bots
- Amazon Connect:
- Receive calls, create contact flows, cloud-based virtual contact center
- Can integrate with other CRM systems or AWS
- No upfront payments, 80% cheaper than traditional contact center solutions
Amazon Comprehend
- For Natural Language Processing(NLP)
- Fully managed and serverless service
- Uses machine learning to find insights and relationships in text
- Language of the text
- Extracts key phrases, places, people, brands, or events
- Understands how positive or negative the text is
- Analyzes text using tokenization and parts of speech
- Automatically organizes a collection of text files by topic
- Sample use cases:
- analyze customer interactions (emails) to find what leads to a positive or negative experience
- Create and groups articles by topics that Comprehend will uncover
Amazon Comprehend Medical
- Amazon Comprehend Medical detects and returns useful information in unstructured clinical text:
- Physician’s notes
- Discharge summaries
- Test results
- Case notes
- Uses NLP to detect Protected Health Information (PHI) – DetectPHI API
- Store your documents in Amazon S3, analyze real-time data with Kinesis Data Firehose, or use Amazon Transcribe to transcribe patient narratives into text that can be analyzed by Amazon Comprehend Medical.
Amazon SageMaker
- Fully managed service for data scientists and developers to prepare, build, train, and deploy high-quality machine learning models
- Typically, difficult to do all the processes in one place + provision servers
- Machine learning process (simplified): predicting your exam score
- ML development activities including:
- Data preparation
- Feature engineering
- Statistical bias detection
- Auto-ML
- Training and tuning
- Hosting
- Monitoring
- Workflows
Amazon Forecast
- Fully managed service that uses ML to deliver highly accurate forecasts
- Example: predict the future sales of a raincoat
- 50% more accurate than looking at the data itself
- Reduce forecasting time from months to hours
- Use cases: Product Demand Planning, Financial Planning, Resource Planning, ...
Amazon Kendra
- Fully managed document search service powered by Machine Learning
- Extract answers from within a document (text, pdf, HTML, PowerPoint, MS Word, FAQs...)
- Natural language search capabilities
- Learn from user interactions/feedback to promote preferred results (Incremental Learning)
- Ability to manually fine-tune search results (importance of data, freshness, custom, ...)
Amazon Personalize
- Fully managed ML-service to build apps with real-time personalized recommendations
- Same technology used by Amazon.com
- Integrates into existing websites, applications, SMS, email marketing systems, ...
- Implement in days, not months (you don’t need to build, train, and deploy ML solutions)
- Use cases: retail stores, media and entertainment...
AmazonTextract
- Automatically extracts text, handwriting, and data from any scanned documents using AI and ML
- Extract data from forms and tables
- Read and process any type of document (PDFs, images, ...)
- Features:
- Optical character recognition (OCR)
- Identifies relationships, structure, and text
- Uses AI to extract text and structured data
- Recognizes handwriting as well as printed text
- Can extract from documents such as PDFs, images, forms, and tables
- Understands context. For example know what data to extract from a receipt or invoice
- Use cases:
- Financial Services (e.g., invoices, financial reports)
- Healthcare (e.g., medical records, insurance claims)
- Public Sector (e.g., tax forms, ID documents, passports)
Amazon Elastic Transcoder
- Transcodes video files to various formats / outputs
- AWS Elemental MediaConvert is a new service that provides more functionality and may be better for new use cases
- Some features are only available on Elastic Transcoder such as:
- WebM (VP8/VP9) input and output
- Animated GIF output
- MP3, FLAC, Vorbis, and WAV audio-only output
- However, MediaConvert offers more options overall
Summary
- Rekognition: face detection, labeling, celebrity recognition
- Transcribe: audio to text (ex: subtitles)
- Polly: text to audio
- Translate: translations
- Lex: build conversational bots – chatbots
- Connect: cloud contact center
- Comprehend: natural language processing
- SageMaker: machine learning for every developer and data scientist
- Forecast: build highly accurate forecasts
- Kendra: ML-powered search engine
- Personalize: real-time personalized recommendations
- Textract: detect text and data in documents
Account Management, Billing & Support
AWS Organizations
A management service that enables you to consolidate multiple AWS accounts into an organization that you create and centrally manage
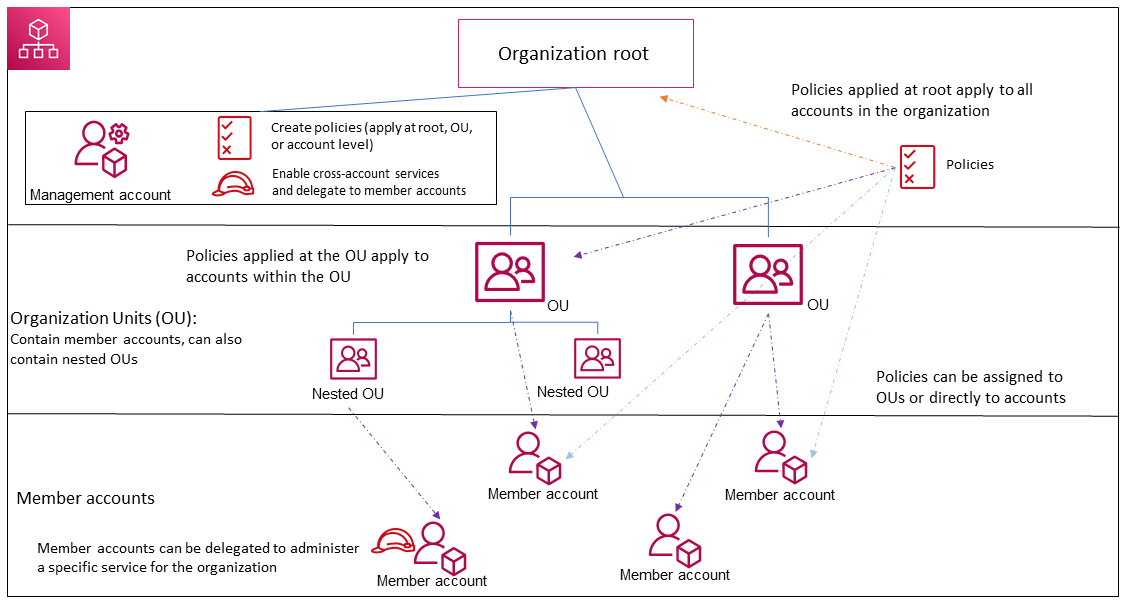
- Global service
- Available in two feature sets:
- Consolidated Billing
- All features
- The main account is the management account
- Other accounts are member accounts
- Member accounts can only be part of one organization
- Cost Benefits:
- Consolidated Billing across all accounts - single payment method
- Pricing benefits from aggregated usage (volume discount for EC2, S3...)
- Pooling of Reserved EC2 instances for optimal savings
- API is available to automate AWS account creation
- Restrict account privileges using Service Control Policies (SCP)
- Includes root accounts and organizational units
- Policies are applied to root accounts or OU(Organization Unit)s
- Consolidated billing includes:
- Paying Account – independent and cannot access resources of other accounts
- Linked Accounts – all linked accounts are independent
Organizations API
The AWS Organizations API can be used to automate organization and account creation
Useful API actions:
CreateOrganization– creates an organizationCreateAccount– creates an account that is a member of the organizationCreatePolicy– creates a policy that can be attached to a root, OU, or individual AWS accountAttachPolicy- Attaches a policy to a root, an organizational unit (OU), or an individual accountInviteAccountToOrganization- Sends an invitation to another account to join your organization as a member account
Service Control Policies (SCP)
- Whitelist or blacklist IAM actions
- Applied at the OU(Organization Unit) or Account level
- Does not apply to the Master Account
- SCP is applied to all the Users and Roles of the Account, including Root user
- The SCP does not affect service-linked roles
- Service-linked roles enable other AWS services to integrate with AWS Organizations and can't be restricted by SCPs.
- SCP must have an explicit Allow (does not allow anything by default)
- Use cases:
- Restrict access to certain services (for example: can’t use EMR)
- Enforce PCI compliance by explicitly disabling services
SCP Strategies and Inheritance
Deny List Strategy:
- The
FullAWSAccessSCP is attached to every OU and account - Explicitly allows all permissions to flow down from the root
- Can explicitly override with a deny in an SCP
- This is the default setup
Note
An explicit deny overrides any kind of allow
Allow List Strategy:
- The
FullAWSAccessSCP is removed from every OU and account - To allow a permission, SCPs with allow statements must be added to the account and every OU above it including root
- Every SCP in the hierarchy must explicitly allow the APIs you want to use
AWS Control Tower
- Easy way to set up and govern a secure and compliant multi-account AWS environment based on best practices -> known as
landing zone - Benefits:
- Automate the set up of your environment in a few clicks
- Automate ongoing policy management using guardrails
- Detect policy violations and remediate them
- Monitor compliance through an interactive dashboard
- AWS Control Tower runs on top of AWS Organizations:
- It automatically sets up AWS Organizations to organize accounts and implement SCPs (Service Control Policies)
- Guardrails are used for governance and compliance:
Preventive guardrailsare based on SCPs and disallow API actionsDetective guardrailsare implemented using AWS Config rules and Lambda functions and monitor and govern compliance
- The root user in the management account can perform actions that guardrails would disallow
AWS Organizations vs Control Tower
- Manage multiple accounts
- Consolidated billing
- Organizational Units
- Service Control Policies
- Tag Policies
- Backup Policies
- Extends capabilities of AWS Organizations
- Landing Zones (best practices)
- Federated Access (IAM Identity Center)
- Centralized Logging
- Account Factory (automation)
- Guardrails (governance rules)
Pricing Models in AWS
- AWS has 4 pricing models:
Pay as you go: pay for what you use, remain agile, responsive, meet scale demandsSave when you reserve: minimize risks, predictably manage budgets, comply with long-terms requirements- Reservations are available for EC2 Reserved Instances, DynamoDB Reserved Capacity, ElastiCache Reserved Nodes, RDS Reserved Instance, Redshift Reserved Nodes
Pay less by using more: volume-based discountsPay less as AWS grows
Billing and Costing Tools
- Estimating costs in the cloud:
- Pricing Calculator
- Tracking costs in the cloud:
- Billing Dashboard
- Cost Allocation Tags
- Cost and Usage Reports
- Cost Explorer
- Monitoring against costs plans:
- Billing Alarms
- Budgets
AWS Compute Optimizer
- Uses machine learning to analyze historical utilization metrics
- Recommends optimal AWS resources for your workloads to reduce costs and improve performance
- Offers optimization guidance for:
- Amazon EC2 instances
- Amazon EBS volumes
- AWS Lambda functions
- Results can be viewed in the console or via the CLI
AWS Cost Explorer
- The AWS Cost Explorer is a free tool that allows you to view charts of your costs
- You can view cost data for the past 13 months and forecast how much you are likely to spend over the next three months
- Cost Explorer can be used to discover patterns in how much you spend on AWS resources over time and to identify cost problem areas
- Cost Explorer can help you to identify service usage statistics such as:
- Which services you use the most
- View metrics for which AZ has the most traffic
- Which linked account is used the most
AWS Cost & Usage Report
- Publish AWS billing reports to an Amazon S3 bucket
- Reports break down costs by:
- Hour, day, month, product, product resource, tags
- Can update the report up to three times a day
- Create, retrieve, and delete your reports using the AWS CUR API Reference
AWS Price List API
- Query the prices of AWS services
- Price List Service API (AKA the Query API) – query with JSON
- AWS Price List API (AKA the Bulk API) – query with HTML
- Alerts via Amazon SNS when prices change
Disaster Recovery
- Backup
- EBS Snapshots, RDS automated backups / Snapshots, etc...
- Regular pushes to S3 / S3 IA / Glacier, Lifecycle Policy, Cross Region Replication
- From On-Premise: Snowball or Storage Gateway
- High Availability
- Use Route53 to migrate DNS over from Region to Region
- RDS Multi-AZ, ElastiCache Multi-AZ, EFS, S3
- Site to Site VPN as a recover y from Direct Connect
- Replication
- RDS Replication (Cross Region), AWS Aurora + Global Databases
- Database replication from on-premises to RDS
- Storage Gateway
- Automation
- CloudFormation / Elastic Beanstalk to re-create a whole new environment
- Recover / Reboot EC2 instances with CloudWatch if alarms fail
- AWS Lambda functions for customized automations
- Chaos
- Netflix has a "simian-army" randomly terminating EC2
Backup Strategies
There are four general ways to set up the backup of your environment that will also support full disaster recovery:
- RPO/RTO: Hours
- Low priority workloads
- Provision/restore after event
- Cost $
- RPO/RTO: 10s of minutes
- Data replicated
- Services idle/off
- Resources activated after event
- Cost $$
- RPO/RTO: Minutes
- Minimum resources always running
- Business critical workloads
- Scale up/out after event
- Cost $$$
- RPO/RTO: Real-time
- Zero downtime
- Near zero data loss
- Mission critical workloads
- Cost $$$$
RPO and RTO
Recovery Point Objective (RPO)
- Measurement of the amount of data that can be acceptably lost
- Measured in seconds, minutes, or hours
- Example:
- You can acceptably lose 2 hours of data in a database (2hr RPO)
- This means backups must be taken every 2 hours
Recovery Time Objective (RTO)
- Measurement of the amount of time it takes to restore after a disaster event
- Measured in seconds, minutes, or hours
- Example:
- The IT department expect it to take 4 hours to bring applications online after a disaster
- This would be an RTO of 4 hours
Achievable RPOs
| Recovery Point Objective | Technique |
|---|---|
| Milliseconds - Seconds | Synchronous replication |
| Seconds - Minutes | Asynchronous replication |
| Minutes to hours | Snapshots, cloud backup, D2D |
| Hours to days | Offsite / traditional backups / tape backups |
Tip
The RPO is determined by how you take a backup of data
Achievable RTOs
| Recovery Time Objective | Technique |
|---|---|
| Milliseconds to Seconds | Fault tolerance |
| Seconds to Minutes | High availability, load balancing, auto scaling |
| Minutes to hours | Cross-site recovery (cloud), automated recovery |
| Hours to days | Cross-site recovery (cloud/on-premises), manual recovery |
Tip
The RTO is determined by how quickly you can recover
AWS Backup
- Fully managed service for automating data protection
- Centralized backup management for many services:
- Compute services such as EC2
- Storage services such as EBS, S3, FSx, and EFS
- Database services such as RDS, DynamoDB, and DocumentDB
- Hybrid applications like VMware workloads on-premises or on VMware Cloud or Outposts
- Policy-based data protection
- Managed through the console, API, and CLI
- Backups are encrypted with AWS KMS keys
- Also provide protection from ransomware
Migration
DataBase Migration - DMS
DMS: Database Migration Service
- Quickly and securely migrate databases to AWS, resilient, self healing
- The source database remains available during the migration
- Use the
Schema Conversion Toolfor heterogeneous migrations - Use Cases:
- Cloud to Cloud – EC2 to RDS, RDS to RDS, RDS to Aurora
- On-Premises to Cloud
- Homogeneous migrations – Oracle to Oracle, MySQL to RDS MySQL, Microsoft SQL to RDS for SQL Server
- Heterogeneous migrations – Oracle to Aurora, Oracle to PostgreSQL, Microsoft SQL to RDS MySQL (must convert schema first wit the Shema Conversion Tool (SCT))
- Development and Test – use the cloud for dev/test workloads
- Database consolidation – consolidate multiple source DBs to a single target DB
- Continuous Data Replication – use for DR, dev/test, single source multi-target or multi-source single target
Server Migration - AWS Server Migration Service (SMS)
- AWS SMS migrates
VMware vSphere,Microsoft Hyper-V/SCVMM, andAzure virtual machinesto Amazon EC2 - Automated, incremental and scheduled migrations
- EC2 instances can be created from the AMIs
- CloudWatch Events and Lambda can automate actions
- Entire application group is launched from AMIs using CloudFormation template
Data Migration - Snow Family
Highly-secure, portable devices to collect and process data at the edge, and migrate data into and out of AWS
AWS Snowball and Snowmobileare used for migrating large volumes of data to AWSSnowball Edge Compute Optimized- Provides block and object storage and optional GPU
- Use for data collection, machine learning and processing, and storage in environments with intermittent connectivity (edge use cases)
Snowball Edge Storage Optimized- Provides block storage and Amazon S3-compatible object storage
- Use for local storage and large-scale data transfer
Snowcone- Small device used for edge computing, storage and data transfer
- Can transfer data offline or online with AWS DataSync agent
AWS OpsHub: A software installed on your computer to manage Snow Family Decives
Usage Process
- Request Snowball devices from the AWS console for delivery
- Install the snowball client / AWS OpsHub on your servers
- Connect the snowball to your servers and copy files using the client
- Ship back the device when you’re done (goes to the right AWS facility)
- Data will be loaded into an S3 bucket
- Snowball is completely wiped
Edge Computing
- Snowcone (smaller)
- 2 CPUs, 4 GB of memory, wired or wireless access
- USB-C power using a cord or the optional battery
- Snowball Edge – Compute Optimized
- 52 vCPUs, 208 GiB of RAM
- Optional GPU (useful for video processing or machine learning)
- 42 TB usable storage
- Snowball Edge – Storage Optimized
- Up to 40 vCPUs,80 GiB of RAM
- Object storage clustering available
- All: Can run EC2 Instances & AWS Lambda functions (using AWS IoT Greengrass)
- Long-term deployment options: 1 and 3 years discounted pricing
Ways to optimize the performance of Snowball transfers
- Use the latest Mac or Linux Snowball client
- Batch small files together
- Perform multiple copy operations at one time
- Copy from multiple workstations
- Transfer directories, not files
Use Cases
- Cloud data migration – migrate data to the cloud
- Content distribution – send data to clients or customers
- Tactical Edge Computing – collect data and compute
- Machine learning – run ML directly on the device
- Manufacturing – data collection and analysis in the factory
- Remote locations with simple data – pre-processing, tagging, compression etc
The 7 Rs of Migration
- Refactor – Re-architect to a cloud-native serverless architecture
- Replatform – Ex. database to RDS; server to Elastic Beanstalk
- Repurchase – Use a different solution (e.g. SaaS)
- Rehost – OS/App moved to another host system (lift & shift)
- Relocate – Move without modification (lift & Shift)
- Retain – Leave as is (revisit at a later date)
- Retire – No longer needed, get rid of it